

Birisi sohbet botunun bir gerçeği neden yanlış söylediğini sorduğunda dürüst yanıt her zaman aynıdır. Model hiçbir şeye bakmıyor. Eğitim sırasında sabit bir metin enstantanesinden öğrendiği örüntülere göre bir sonraki kelimeyi, sonra bir sonrakini, sonra bir sonrakini üretiyor. Senin kod tabanına dair bir hatırası yok, dünkü toplantı notlarının bir kopyası yok, ve halüsine ettiği API'nin geçen çeyrek yeniden adlandırıldığına dair en ufak bir fikri yok. Donmuş bilgiyle parlak bir örüntü tanıyıcısıdır, ve bu kısıtlamaya en yaygın çare retrieval-augmented generation, kısaca RAG denilen bir tekniktir. Fikir tek bir cümleye sığacak kadar küçüktür, ama etrafındaki mühendislik bir kariyeri dolduracak kadar ilginçtir: sorgu anında, kontrol ettiğin bir korpustan en alakalı pasajları bul, prompt'a yapıştır, ve modelden bu metni kullanarak yanıtlamasını iste. Aynı model, daha akıllı girdi.
Bu yazı o tek cümlenin uzun versiyonu. Yanından çalışan bir zihinsel modelle ayrılmanı istiyorum: sade çıkarım ne yapıyor, RAG buna ne ekliyor, dikişler nerede, ve hydra-llm gibi bir yığın tüm hattı nasıl kendi dizüstünde çalıştırabileceğin birkaç komuta sığdırıyor. Önceden makine öğrenmesi bilgisi gerekmiyor. Teknik bir terim kullanmam gerektiğinde, kullanmadan önce tanımlayacağım.

Sade çıkarım, mümkün olan en basit haliyle, bir sohbet arayüzüne mesaj yazdığında ve model yanıt verdiğinde olan şeydir. Model bir fonksiyondur. Fonksiyon bir token dizisi alır (token, alt-kelime parçasıdır, İngilizcede ortalama dört karakter civarı) ve bir sonraki token üzerinden bir olasılık dağılımı çıkarır. Çalışma zamanı bu dağılımdan bir token örnekler, girdiye ekler ve fonksiyonu yeniden çalıştırır. Model bir durdurma tokeni yayana ya da uzunluk sınırına çarpana kadar tekrar eder. Bütün numara en altta budur.
Buradan anlamlı yanıtların çıkmasının nedeni, fonksiyonun parametrelerinin (eğitim sırasında ayarlanan milyarlarca sayının) metnin nasıl yazıldığına dair olağanüstü miktarda istatistiksel düzenliliği kodlamasıdır. Bir modeli açık webin geniş bir diliminde, kitaplarda, kodda ve sentetik veride eğit, dil ve dünya hakkında o kadar çok şey öğrenir ki bir sonraki token dağılımı çoğu zaman doğru yanıtı işaret eder. Ama bildiği her şey o parametrelerin içinde yaşar. Modelin danıştığı bir veritabanı yoktur. Bir bilgi denetleyicisi yoktur. Çıktı, girdinin kendine güvenen bir devamıdır, ve kendine güvenen ile doğru aynı şey değildir.
Sade çıkarımın öngörülebilir üç yolla başarısız olmasının nedeni budur. Eğitim verilerinde olmayan gerçeklerde başarısız olur, yani kesim tarihinden sonra olan her şeyde. Eğitim verilerinde olan ama daha yaygın alternatiflerin altına gömülmüş gerçeklerde başarısız olur, çünkü dağılım yanlış yanıtı tercih eder. Ve sana özgü her şeyde başarısız olur (kodun, sözleşmelerin, müşterilerin, özel belgelerin), çünkü bunların hiçbiri zaten eğitime girmemişti. Sade çıkarım daha çok çabalamayla bunu çözmez. Bilgi fonksiyonun içinde değildir, hepsi bu.
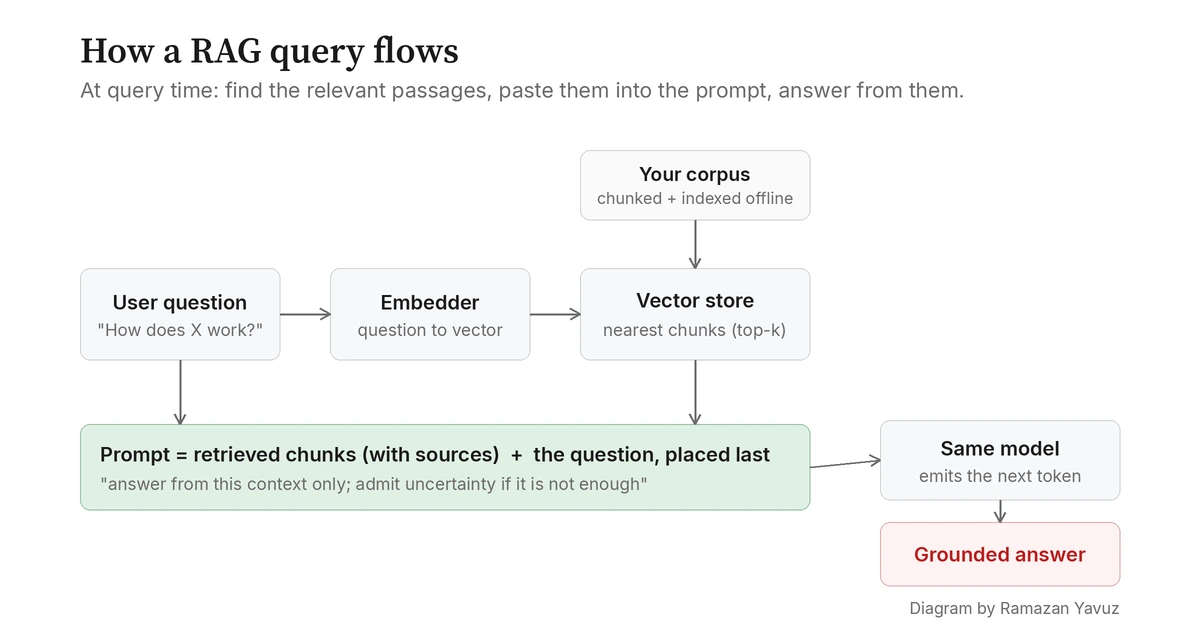
RAG, fonksiyonun iyi olduğu gözleminden başlar. Model mükemmel nesir yazar; sadece senin gerçeklerini bilmez. Yani modeli değiştirmek yerine girdiyi değiştir. Kullanıcının sorusunu modele göndermeden önce, kontrol ettiğin bir korpustan en alakalı pasajları çek, bu pasajları bağlam olarak prompt'a yapıştır, ve modelin zaten iyi olduğu şeyi yapmasına izin ver: metin oku ve buna dayanan tutarlı bir yanıt yaz.
Modelin bakış açısından neredeyse hiçbir şey değişmez. Hâlâ bir prompt alır ve bir sonraki tokeni yayar, ve bir sonrakini, ve bir sonrakini. Değişen şu: prompt artık yanıtı, ya da en azından yanıtın çıkarılabileceği kaynağı içerir. Zor olan kısım model değildir. Zor olan kısım doğru pasajları bulmaktır.
"Doğru pasajlar", bir RAG sistemindeki ilginç her kararın yaşadığı yerdir. Tüm bilgi tabanını prompt'a yapıştıramazsın; modelin sınırlı bir bağlam penceresi vardır (aynı anda okuyabileceği maksimum token sayısı), ve pencere büyük olsa bile, daha fazla bağlam daha fazla zaman, daha fazla bellek ve modelin ince yaymak zorunda olduğu daha fazla dikkat bütçesi demektir. Yani alma adımı seçici olmalıdır: belki milyonlarca tokenlık kaynaktan, tam bu soru için önemli olan birkaç bin tokeni yüzeye çıkarmak.
Seçici almayı büyük ölçekte mümkün kılan numara vektör araması denir, ve altındaki yapı taşı embedding denir. Embedding, bir metin parçasının anlamını temsil eden sabit boyutta bir sayı listesidir (bir vektör). Küçük bir embedding 384 sayı uzunluğunda olabilir; büyük bir embedding birkaç bin. Sayıların kendisi yorumlanabilir değildir. Önemli olan: anlamları benzer iki metin yüksek boyutlu uzayda birbirine yakın vektörler üretir, anlamları alakasız iki metin ise birbirinden uzak vektörler üretir.
Embedding'leri embedder denilen özel bir tür dil modelinden alırsın. Dışarıdan bir sohbet modeline benzer (metin verirsin, geri bir şey alırsın), ama bir sonraki tokeni yaymak yerine tüm girdiyi özetleyen sabit boyutlu bir vektör yayar. Embedder'lar genelde küçüktür (küçük biri için 30 megabyte'tan büyük biri için birkaç gigabyte'a kadar), sohbet modellerinden çok daha küçüktür, çünkü işleri daha dardır. Bazıları nesir için ayarlanmıştır. Bazıları kod için. En iyi modern embedder'lar her ikisi için de ayarlanmıştır ve yaklaşık 768 ile 4096 boyutta vektörler üretir.
Bir embedder'ın varsa, indeksleme adımı şuna benzer. Korpustan yürü. Her belgeyi parçalara ayır; bunlar birkaç yüz kelimelik kısa, büyük ölçüde kendi kendine yeten pasajlardır. Her parçayı embedder'dan geçir. Sonuçta çıkan vektörü, orijinal metinle ve kaynak dosyaya işaret eden bir göstergeyle birlikte, vektör benzerliğine göre arama yapabilen bir veritabanına kaydet. Bu veritabanına vektör deposu denir; LanceDB, FAISS ve Qdrant yaygın seçimlerdir. Sonuç, bilginin her parçasının anlam-uzayında bir koordinata sahip olduğu bir indekstir.
İndeksi sorgulamak ayna görüntüsüdür. Kullanıcının sorusunu al. Aynı embedder'dan geçir. Şimdi parçalarınla aynı anlam-uzayında bir sorgu vektörün var. Vektör deposundan, vektörü bu sorguya en yakın olan parçaları, bir mesafe ölçüsüne göre (genelde kosinüs benzerliği) iste. En iyi birkaç parça geri gelir. Bunlar "bu soruyu muhtemelen yanıtlayan pasajlar" için adaylarındır. Temelde, anlam-farkında bir arama motorudur.
Alma işini bitirdiğinde, prompt birleştirme sıkıcı ama yük taşıyan orta adımdır. Vektör deposunun döndürdüğü parçaları al ve modele göndereceğin gerçek mesajı oluştur. Tek bir doğru biçim yoktur, ama çoğu sistem şuna benzer bir şey yapar: modelin nasıl davranacağını söyleyen kısa bir sistem talimatı, her parçası kaynağıyla etiketlenmiş, ayrılmış bir alınmış bağlam bloğu, ve son olarak kullanıcının sorusu.
Sen bir asistansın. Aşağıdaki bağlamı kullanarak soruyu yanıtla.
Bağlam yanıtı içermiyorsa bilmediğini söyle.
<context>
--- src/auth/middleware.go:42-78 ---
func authenticate(r *http.Request) ...
--- README.md:54-72 ---
Auth flow: every request must carry an X-Api-Key header ...
</context>
Soru: auth tokenlarını nerede ele alıyoruz?Bu prompt'taki üç küçük detay işin çoğunu yapar. Birincisi, parçalar kaynaklarıyla etiketlidir; böylece model alıntı yapabilir ve sen ne dediğini doğrulayabilirsin. İkincisi, sistem talimatı modele sadece bağlamdan yanıtlamasını ve bağlam yetmiyorsa belirsizliği itiraf etmesini söyler; bu talimat olmadan modeller eğitimli bilgilerine geri çekilip onu sessizce alınmış metinle karıştırma eğilimindedir, ve bu tam olarak kaçınmaya çalıştığın başarısızlık modudur. Üçüncüsü, kullanıcının sorusu en sona gelir, çünkü modeller uzun bir bağlamın başını ve sonunu ortasından daha güvenilir kullanır (Liu ve diğerlerinin "lost in the middle" dediği etki), ve iyi dikkat edilen son konumdaki bir soru, model yanıtlamaya başladığında odakta kalmaya daha yatkındır.
Sonra model sıradan çıkarımı yürütür. Daha önceki aynı fonksiyon. Aynı sonraki-token döngüsü. Değişen tek şey, girdinin artık korpustan ilgili parçaları içermesi, böylece en olası sonraki tokenler modelin donmuş eğitim hatırasından değil bu metinden beslenenlerdir.
Bunu bir karşıtlık olarak söylemek yardımcı olur. Sade çıkarım tek bir gidiş-dönüş: soru girer, yanıt çıkar, model yalnızca eğitimde öğrendiğini kullanır. RAG iki gidiş-dönüş: soru önce embedder'a ve vektör deposuna giderek bağlam çeker, sonra soru artı bu bağlam birlikte sohbet modeline gider. Kullanıcı bir kutu görür; sistem iki hat işletir.
Pratik farklar buradan çıkar. Sade çıkarım daha hızlıdır, çünkü tek bir model çağrısı vardır. RAG, verine özgü her şeyde daha doğrudur, çünkü yanıt modelin az önce okuduğu metinde demirlidir. Sade çıkarım kendinden emin halüsine edebilir, çünkü modelin kendini denetlemesinin yolu yoktur. RAG de halüsine edebilir, ama parçalar prompt'ta öyle dururlar ki, iyi yapılmış bir arayüz onları kullanıcıya gösterebilir ve yanıt doğrulanabilir hale gelir. Sade çıkarım dün gece yazdığın bir belge hakkında bir şey söyleyemez, çünkü o belgeyle eğitilmemiştir. RAG söyleyebilir, çünkü yeni bir belgeyi indekslemek tek satırlık bir işlemdir.
RAG'ın düzeltmediği şeyler hakkında dürüst olmak değer. RAG modele yeni akıl yürütme becerisi vermez; alttaki model çok adımlı muhakemede zayıfsa, iyi bağlam çekmek onu kurtarmaz. RAG halüsinasyonu ortadan kaldırmaz; model yanlış aktarabilir, iki parçayı karıştırabilir, ya da prompt şablonun derbederse bağlamı tamamen yok sayabilir. RAG mahremiyeti sihirli bir şekilde korumaz; sırlarla dolu bir klasörü indeksler ve sonra sohbeti birine açarsan, sırlarını az önce ifşa ettin. RAG, yetkin bir modele daha iyi metin beslemenin bir yoludur. Modelin yine yetkin olması gerekir, ve etrafındaki sistemin yine dürüst tasarlanması gerekir.
Yerel yığına geçmeden önce anlamaya değer bir incelik daha var. Saf vektör araması tek alma yolu değildir. Anahtar kelime araması (ya da sözcüksel arama, ya da belirli bir sıralama formülünden BM25) denilen çok daha eski bir teknik vardır; sorgudaki gerçek kelimeleri belgelerdeki gerçek kelimelerle eşleştirir. Vektör araması anlamda iyidir ("auth token", embedder ikisinin akraba olduğunu bildiği için "API key"den bahseden bir parçayı bulur). Anahtar kelime araması tam eşleşmelerde iyidir ("X-Api-Key", embedder bu dizgeyi hiç duymamış olsa bile tam bu dizgeyi içeren parçayı bulur).
İkisi birbirini tamamlar. Modern RAG sistemleri sıkça her ikisini de çalıştırır, her birinden en üst sonuçların listesini alır ve bir füzyon algoritmasıyla birleştirir. Şu an en popüler füzyon algoritması Reciprocal Rank Fusion diye geçer, ve hoş bir özelliği vardır: saçma derecede basittir. Her sonuç, içinde bulunduğu her liste için 1 / (k + sıra) skoru alır, skorlar toplanır, ve toplama göre sıralarsın. k küçük bir sabittir, onu tanıtan makalede tipik olarak 60. Bütün formül bu. Bu kadar iyi çalışmasının nedeni, iki sistemin altta yatan skorlarının aynı ölçekte olmasını gerektirmemesi; sadece sıralı bir liste üretmelerini gerektirmesidir. Aynı füzyon fikri, kodu ve nesri ayrı indekslediğinde (kod embedder'ı genelde kodda daha iyi, nesir embedder'ı genelde nesirde daha iyidir) ve tek bir soru için her iki indeksi de sorgulamak istediğinde de geçerlidir.
Yukarıdakilerin hepsi teori. Somutlaştırmak için yerel bir RAG yığınının parçaları gerçekte nasıl bağladığını adım adım gezmek istiyorum, ve en iyi bildiğim kendiminkidir. hydra-llm (proje sayfası, GitHub'daki kaynak), llama.cpp'yi Docker'da saran küçük bir CLI'dır, model başına stabil bir yerel portta OpenAI uyumlu bir uç nokta sunar, ve almayı sonradan eklenmiş bir özellik olarak değil first-class olarak ele alır. Birazdan tarif edeceğim her şey kendi makinende çalışır, bulutsuz, API anahtarsız, telemetrisiz. Bütün mesele şu: hiçbir şey kutudan çıkmaz.
hydra-llm'nin önüne koyduğu parçalar, önceki bölümlerin tanıttıklarıyla tam olarak aynı, yazabileceğin isimlerle:
| Yazıdaki kavram | hydra-llm'de somut parça |
|---|---|
| Sohbet modeli (yanıtı yazan fonksiyon) | Küratörlü katalogdan bir model çalıştıran bir llama.cpp konteyneri (Llama, Gemma, Qwen, Mistral, vb.) |
| Embedder (metni vektörlere çeviren fonksiyon) | --embeddings modunda ayrı bir llama.cpp konteyneri, kutuda gelen altı embedder'dan birini çalıştırır (nomic-embed-text, qwen3-embed-{0.6b,4b,8b}, bge-m3, nomic-embed-code) |
| Vektör deposu (parçaların veritabanı) | <klasörün>/.hydra-index/ içinde yaşayan bir LanceDB deposu, kod ve nesir için ayrı tablolar |
| Hibrit alma (vektör artı anahtar kelime, füzyonlu) | Kod ve nesir tabloları üzerinde Reciprocal Rank Fusion, her sorguda otomatik çalışır |
| Prompt birleştirme (bağlamı soruya yapıştırma) | Sohbet komutunun --rag bayrağı: her kullanıcı mesajı embedlenir, en üst-K parça çekilir, ve mesaj modele gitmeden önce bir <context> bloğuna sarılır |
Kullanıcı tarafından koreografi kısa. Bir komut embedder'ları kurar. Bir komut bir klasörü indeksler. Bir komut, her turda alma yapan bir sohbet başlatır.
# 1. Donanımına göre boyutlandırılmış embedder'ları çek
hydra-llm rag setup
# 2. Bir klasörü indeksle. Ağacı yürür, her dosyayı kod ya da
# nesir olarak sınıflandırır, satır farkında parçalar (1500
# karakter hedef, 200 örtüşme), her parçayı embedler ve her
# şeyi ./.hydra-index/'e yazar
cd ~/projects/cool-app
hydra-llm index .
# 3. Her turda alma yapan bir sohbet
hydra-llm chat llama-3.1-8b --rag .--rag .'nin arkasında olan, tam olarak yukarıdaki iki-hat resmidir. Bir mesaj yazarsın. hydra-llm onu embedder konteynerine gönderir, geri bir sorgu vektörü alır, LanceDB'den her iki tabloda en iyi eşleşen parçaları ister, iki listeyi Reciprocal Rank Fusion ile füzyonlar, üst-K hayatta kalanları alır, her parçası dosya yolu ve satır aralığıyla etiketlenmiş bir <context> bloğu kurar, mesajının önüne ekler, ve ancak ondan sonra birleştirilmiş prompt sohbet konteynerine gider. Sohbet konteyneri tokenleri geri stream'ler. Aynı model, aynı çıkarım döngüsü, daha akıllı girdi.
Bu hattaki birkaç ayrıntıya parmakla işaret etmeye değer, çünkü her RAG sisteminin vermek zorunda olduğu kararlardır ve aldığın yanıtları biçimlendirir. Parçalayıcı satır farkındadır: bir parçayı asla satır ortasında bölmez, ki bu nesirden çok kodda önemlidir. Dosyalar parçalanmadan önce sınıflandırılır: kod dosyaları kod embedder'ına, nesir dosyaları nesir embedder'ına gider, çünkü bir README üzerinde kod embedder'ı kullanmak nesir vektörünü mahveder ve tersi de geçerlidir. İndeks klasörle birlikte taşınır: .hydra-index/ dizini dosyalarının yanında oturur, yani bir projeyi başka makineye kopyalamak indeksi de bedavaya götürür. Artırımlı güncellemeler dosya değiştirme zamanına ve boyutuna göredir: hydra-llm index .'yi yeniden çalıştırmak yalnızca gerçekten değişen dosyaları yeniden embedler.
hydra-llm'nin tek başına anılmaya değer bir özelliği "katalog-bağlı paketler" dediği şeydir. Bir sohbet katalog girdisi bir sistem prompt'unu, örnekleme parametrelerini ve bir rag_index: yolunu tek bir bildirimsel birim olarak birlikte taşıyabilir. Bir kez paket create ettiğinde, onunla sohbet etmek tek kelimedir:
hydra-llm create llama-3.1-8b ~/personas/senior-engineer.md cool-app-bot \
--rag-index ~/projects/cool-app
hydra-llm chat cool-app-bot # bayraksız, alma kendiliğinden çalışırTüm döngü, bir isimde donmuş halde. Paket diyor ki: bu model, bu personayla, bu korpustan alma yaparak, her tur. Bir iş akışını anlatmakla onu kullanmak arasındaki fark.
Döşeme tahtalarının altına bakmak isteyenler için: parçalar kaynak kodda kabaca böyle bağlanmış. Tüm RAG hattı v0.2.0 ile geldi, 87b27e3 commit'i (sürüm etiketi) ve özellik dalını main'e getiren merge, 0b4c7e1 commit'i. Dal review edilebilir dört aşamaya bölündü, ve her birinin pişirdiği tasarım kararları adıyla anılmaya değer, çünkü her RAG sisteminin vermek zorunda olduğu aynı kararlardır.
Aşama 1a: 5d6387c embedder kataloğu. Embedder'lar ayrı bir model türü olarak ele alınır, "embed eden sohbet modelleri" değil. Kendi kataloglarında ~/.config/hydra-llm/embedders.yaml altında yaşarlar, kendi indir/listele/info alt komutları ve sohbet modelleriyle çakışmamak için kendi port aralıkları vardır. Bunun arkasındaki karar sıradan ve önemli: bir embedder uzun ömürlü bir sidecar'dır. İndeksleme ve alma yapan her sohbet turu için çalışıyor olmalı, ama aksi takdirde görünmezdir. Onu kendi şeyi olarak modellemek bu yaşam döngüsünü dürüst tutar.
Aşama 1b: 44dd621 embedder sidecar'ları ve embeddings istemcisi. Her embedder, OpenAI /v1/embeddings formatını stabil bir portta sunan kendi llama.cpp konteynerinde --embeddings modunda çalışır. İstemci istekleri batchler, vektörleri normalleştirir (böylece kosinüs benzerliği aşağıda nokta çarpıma indirgenir), ve geri kalan kodun embedding'i "metin ver, numpy dizisi al" gibi ele almasını sağlar.
Aşama 1c: cb78cd9 yürüyücü, sınıflandırıcı ve satır farkında parçalayıcı. Alma kalitesinin bağlı olduğu ağır işin çoğunu yapan üç dürüst küçük fonksiyon. Yürüyücü ağaçtaki her .gitignore'a saygı duyar, artı sabit kodlu bir node_modules, .venv, target, kilit dosyaları, ikilikler, arşivler, medya ve ağırlıklar kara listesi vardır, ve 1 MB'tan büyük ya da UTF-8 çözümünden geçmeyen dosyaları atlar. Sınıflandırıcı dosya başına kod ya da nesir seçer: önce uzantı (yani install.sh doğru biçimde kod olur, sırf bir README'nin yanında durduğu için nesir değil), sonra kanonik temel adlar (Makefile, Dockerfile kod; README, LICENSE nesir), sonra uzantısız scriptler için bir shebang sniff'i. Parçalayıcının yumuşak hedefi 200 karakter örtüşmeyle 1500 karakterdir, ama hiçbir zaman satır ortasında kesmez, ki bu önemsiz gibi gelir, değildir: bir fonksiyon imzasının ortasında biten bir parça alma için gerçekten işe yaramazdır, çünkü embedder yarım bir düşünceyi vektörler.
Aşama 1d: 2c98ade LanceDB depolaması ve indeks hattı. Her şeyin bir araya geldiği yer burası. Her indekslenen klasör iki LanceDB tablosuyla (code.lance, prose.lance), indeksin hangi embedder kimlikleriyle inşa edildiğini kaydeden bir meta.yaml ile, ve her indekslenen dosyayı (yol, boyut, mtime, parça-kimlikleri) ile listeleyen bir files.json ile bir .hydra-index/ büyütür. Bu aşamadaki iki tasarım kararı tüm kullanıcı deneyimini şekillendirir: artırımlı yenileme dosyaları (boyut, mtime) ile diff'ler, böylece bir klasörü yeniden indekslemek ikinci koşturmada hızlıdır; ve kaydedilen embedder kimlikleri artık şimdi seçilenlerle eşleşmiyorsa zorla bir yeniden inşa otomatik olarak ateşlenir, çünkü farklı embedder'lardan vektörleri karıştırmak almayı sessizce yıkar, ve bir dakikayı yeniden embedlemekle harcamak, yanıtların neden kötüleştiğini bir hafta merak etmekten çok daha iyidir.
Aşama 2: ef7b4cf alma ile sohbet ve federe sorgu. chat --rag yolu her kullanıcı mesajını embedler, her iki tabloya karşı k-en yakın komşu araması yürütür, sonuçları k=60'ta Reciprocal Rank Fusion ile füzyonlar, ve birleştirilmiş prompt'u sohbet modeline göndermeden önce hayatta kalanları bir <context> bloğuna sarar. --rag-all bu almayı makinedeki her indekslenen klasör arasında federe eder; --rag-tag bir etiketi paylaşan klasörler arasında federe eder. Kaydedilen sohbet oturumları orijinal (zenginleştirilmemiş) metni saklar, zenginleştirilmiş versiyonu değil, böylece bir oturumu sürdürmek yeni turu eski bağlamla zehirlemez.
Aşama 3: de360fe katalog-bağlı paketler. Bir sohbet katalog girdisi system_prompt ve params'ın yanı sıra doğrudan bir rag_index: alanı taşıyabilir. create, model + persona + korpus yolunu tek bir bildirimsel takma ada pişirir, ve o noktadan sonra chat <takma-ad> bayraksız tüm iş akışını yeniden üretir. Katalog dosyası makineler arasında kopyalayabileceğin sade YAML.
Diff boyunca üç başka karar daha öne çıkıyor ve kayda değer, çünkü inşa ettiğin ikinci ya da üçüncü RAG sisteminden sonra öğrendiğin türden şeyler. Kod ve nesir varsayılan olarak farklı embedder'lar kullanır, çünkü bir kod embedder'ı uzun bir README üzerinde nesir embedder'ından daha kötü bir vektör üretir, ve tersi de geçerlidir; sonraki sürümler (0e9b939, 687d7ed) çift indeksi opsiyonel, tek embedder'ı yeni varsayılan yaptı, çünkü çoğu kullanıcı klasörü için daha basit kurulum aynı kadar iyi alır ve diskin yarısı ile embedding süresinin yarısını kullanır. Vektörler yazma anında normalleştirilir, böylece LanceDB sorgu yolu satır başına kosinüs benzerliği hesaplamak yerine nokta çarpımları yapar. İndeks kaynağıyla aynı yerde tutulur: ~/projects/cool-app'i başka bir makineye kopyalarsan, .hydra-index/ de gider, ve aynı embedder'lar kuruluysa indeks orada anında çalışır. Bunların hiçbiri egzotik değil; hepsi indekslenen korpusun bir oyuncaktan büyük olduğu anda gerçek zaman tasarrufu sağlar.
Buradan tek bir şey alacaksan, zihinsel model olsun. Tek başına bir dil modeli, donmuş bilgiyle parlak bir metin devamı motorudur. RAG motoru değiştirmez; yakıtı değiştirir. Modelin önüne bir arama adımı koyup ona kontrol ettiğin bir korpustan en alakalı pasajları besleyerek, sabit hatıralı kapalı bir fonksiyonu, koduna, notlarına, sözleşmelerine ya da yarım dakika önce indekslediğin her şeye dair yanıt verebilen bir sisteme dönüştürürsün. Modelin yine okumakta ve yazmakta iyi olması gerekir. Almanın yine doğru metni bulması gerekir. Prompt'un yine dürüstçe birleştirilmesi gerekir. Üç parça da yerinde olunca, sonuç insanların "kendi verim için bir AI asistanı" duyduklarında hayal ettikleri şeydir: hızlı, demirli ve doğrulanabilir, ortada gizemli bir bulut adımı olmadan.
İşte tam olarak bu son kısım (gizemli bulut adımı yok), bunu yerel inşa etmenin bir meraktan daha fazlası olmasının nedenidir. Korpus senin, embedder senin, sohbet modeli senin, ve indeks diskini terk etmiyor. Verin hassasıysa, mantıklı olan tek mimari budur. Verin hassas değilse, yine de sana en fazla kontrolü ve en düşük değişken maliyeti veren mimaridir. RAG dil modellerini düzelten sihirli bir katman değil. Modelin yanıtlamadan önce neyi okuyabileceğine senin karar vermeni sağlayan dikkatli bir hat. Döngüyü birkaç kez kendin işlettiğinde, modellerin neyi bilip neyi bilmediği seni şaşırtmayı bırakır.