

Yerel LLM\'ler kafa karıştırıcı bir çeşitlilikte dosya varyantlarında gelir. Aynı model, diyelim ki 14 milyar parametreli bir Mistral, bir topluluk nicemleyicisinin deposunda mistral-14b-Q4_K_M.gguf, mistral-14b-Q5_K_S.gguf, mistral-14b-Q6_K.gguf, mistral-14b-IQ3_XXS.gguf ve bir düzine başkası olarak görünür. Hepsi aynı ağırlık ağıdır, sadece farklı şekillerde sıkıştırılmıştır. Sıkıştırmaya nicemleme diyoruz, ve isimler size hangi tür sıkıştırmanın uygulandığını tam olarak söyler. Onları okuyabildiğinizde tahmin etmeyi bırakırsınız.
Bir sinir ağı çok uzun bir sayı listesidir. Bu sayılar ağırlıklardır, ve eğitim sırasında 32-bit veya 16-bit kayan nokta değerleri olarak depolanmıştır. 16-bit\'te 7 milyar parametreli bir model 14 GB ağırlıktır. 16-bit\'te 70 milyar parametreli bir model 140 GB\'tır. Çoğu tüketici GPU\'su ikisini de tutamaz, ve sistem RAM\'i bile büyük olanlarda zorlanır. Bu yüzden sıkıştırırız.
Nicemleme, "her ağırlığı daha az bit\'te depolayın"ın süslü bir ifadesidir. 16 bit kullanan bir ağırlık 4 bit ile yaklaşıklaştırılabiliyorsa, dosya dört kat küçülür. Model yine çalışır; sadece kendisinin biraz daha az hassas bir versiyonundan çalışır. Sanat, modelin davranışını bozmayacak şekilde hassasiyetin nerede kaybedileceğini seçmektir.
Saf 4-bit depolama en basit şema olurdu: her ağırlığı al, 16 olasılık arasından en yakın temsil edilebilir değeri seç, indeksi sakla. Bu çalışır, ama çok şey kaybeder. Modern formatlar daha akıllıdır. Ağırlıkları küçük bloklara gruplarlar (tipik olarak blok başına 32 değer) ve her blok içinde paylaşılan bir ölçek faktörü ve bazen bir offset depolarlar. Yani "bu ağırlık 0..15\'ten 5 tamsayısıdır" yerine "bu ağırlık 0..15\'ten 5\'tir, bloğun 0,0042 ölçeğiyle çarpılır, bloğun offset\'i eklenir" olur. Bu küçük blok başına kalibrasyon, hassasiyetin çoğunu geri getirir.
İsimlerdeki harfler buradan gelir. K, Iwan Kawrakow\'un llama.cpp\'ye getirdiği ve naif bit kesilmesinden çok daha iyi bir kalite-boyut oranı elde etmek için bu blok başına ölçekleri (ve birkaç başka hile) kullanan k-quant formatları ailesini ifade eder. I, formatın modelin yoğun olarak güvendiği ağırlıklara daha fazla bit, daha az katkıda bulunan ağırlıklara daha az bit harcadığı önem-farkında nicemlemeyi ifade eder. Model, önemli olan kısımlardaki keskinliğini korur.
İsimler bir desen izler. İlk kısım depolama şemasıdır, ikinci kısım bit sayısıdır, ve sonek boyut varyantıdır. Aslında karşılaşacağınız en yaygın olanları size sıralayayım.
Q2_K, Q3_K, Q4_K, Q5_K, Q6_K, Q8_K: ağırlık başına 2, 3, 4, 5, 6 ve 8 bit\'lik k-quant formatları. Daha yüksek sayı, ağırlık başına daha fazla bit demektir, bu da daha büyük dosya ve daha iyi kalite anlamına gelir. Q8_K orijinal 16-bit dosyadan esasen ayırt edilemez. Q2_K yoğun şekilde sıkıştırılmıştır ve gözle görülür şekilde daha kötüdür.
Sonek _S, _M veya _L, bir bit bütçesi içindeki boyut varyantıdır. Formatın bit bütçesini modelin farklı kısımlarına nasıl yaydığını kontrol ederler. _S en küçüktür ve en agresiftir. _L en büyüğüdür ve en cömertidir. _M ortada durur.
IQ1_S, IQ2_XS, IQ2_XXS, IQ2_S, IQ3_XXS, IQ3_XS, IQ3_S, IQ3_M, IQ4_XS, IQ4_NL: önem-farkında varyantlar. Aynı okuma: sayı ağırlık başına bittir, sonek boyut varyantıdır. XXS ve XS boyutları, yalnızca önem-farkındalığı sayesinde pratik hale gelen agresif düşük-bit ayarlarıdır; o olmadan, 3-bit altı nicemleme çoğu model için kullanılamaz olurdu.
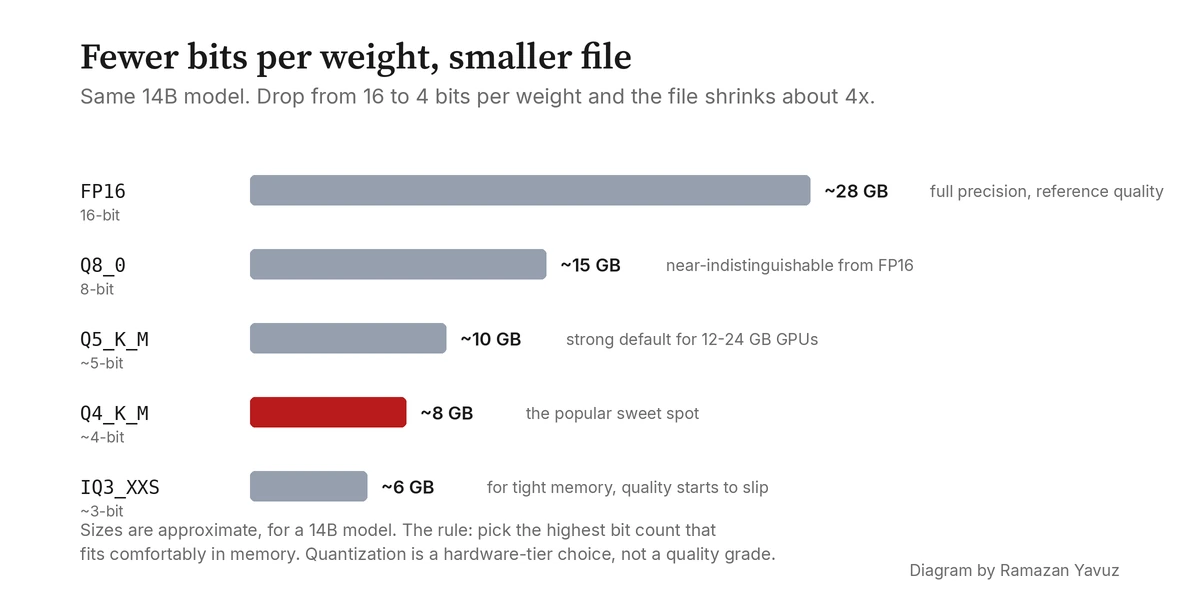
14 milyar parametreli bir model size ödün için bir his verir. F16\'da (orijinal 16-bit format) diskte yaklaşık 28 GB\'tır ve bellekte de aynısı. Q8_K\'da çoğu benchmark\'ta ölçemeyeceğiniz bir kalite kaybı ile yaklaşık 15 GB\'a küçülür. Q6_K\'da konuşmada ölçemeyeceğiniz bir kalite kaybı ile yaklaşık 11 GB\'tır. Q4_K_M\'de yaklaşık 8,5 GB\'tır; bu çoğu insanın tüketici GPU\'ları için kondukları sweet spot\'tur, ve bu hydra-llm\'in tier yapılandırmasında varsayılan aldığım kademedir. Kalite kaybı küçüktür ama zorlu prompt\'larda ölçülebilir hale gelmeye başlar.
Bunun altında işler daha hızlı bozulur. Q3_K_M yaklaşık 6,5 GB\'tır ama model uzun, yapılandırılmış görevlerde daha kafası karışık olur. Q2_K yaklaşık 5 GB\'tır ve görünür şekilde daha kötü çıktılar üretmeye başlar. IQ3_XXS, sadece yaklaşık 5,5 GB olmasına rağmen, bit bütçesi daha akıllıca tahsis edildiği için aynı boyuttaki Q3_K_S\'i çoğunlukla geride bırakır. Bu, önem-farkında nicemlemenin tek cümlelik özetidir: aynı kalitede daha küçük dosyalar veya aynı boyutta daha iyi kalite.

Donanım ne çalıştırabileceğinizi belirler. İlk kısıt bellektir. Model GPU\'nuzun VRAM\'ine sığmalı (veya yalnızca CPU çıkarımı yapıyorsanız, OS için bir miktar boş alanla sistem RAM\'inize). GPU\'nuzun 12 GB VRAM\'i varsa ve model dosyası 14 GB ise, onu yükleyemezsiniz; daha küçük bir nicemlemeye düşmek veya CPU ve GPU arasında bölmek zorundasınız, ki bu çok yavaşlatır.
İkinci kısıt bant genişliğidir. Daha düşük bit\'li nicemlemeler ağırlık başına daha az bayt okur, ki bu saniyede daha fazla ağırlık çekildiği anlamına gelir. Bant genişliği sınırlı donanımda (ki çoğu tüketici GPU\'su ve neredeyse tüm entegre GPU\'lar bu) düşük-bit nicemlemeler aslında sadece daha küçük değil, daha hızlı çalışır. Bir Q4_K_M, GPU sadece daha az veri taşıdığı için aynı modelin Q8_K\'sından çoğunlukla 1,5 ila 2 kat daha hızlı token üretir.
Bu yüzden nicemlemeyi bir kalite kararı yerine bir donanım-kademe kararı olarak ele alıyorum. Bellekte rahatça sığan ve size kabul edilebilir hız veren en yüksek bit sayısını seçin; bu sizin sweet spot\'unuzdur. 12 ila 24 GB\'lık çoğu modern tüketici GPU için Q4_K_M ile Q6_K arası pratik banttır. Çok dar bellek bütçesine sahip makineler için IQ formatları size aşağı doğru daha akıllıca bir yol verir.
Hızlı referans için bir tabloya sıkıştırılmış birkaç yaygın etiket. Boyutlar 14 milyar parametreli bir model için yaklaşıktır.
| İsim | Bit/ağırlık | Yakl. boyut (14B) | Ne zaman kullanılır |
|---|---|---|---|
F16 / BF16 | 16 | ~28 GB | Belleğiniz var ve orijinali istiyorsunuz. |
Q8_K | 8 | ~15 GB | Yarı boyutta etkili olarak orijinal kalite. |
Q6_K | 6 | ~11 GB | Mükemmel kalite, 16 GB kartlara rahat sığar. |
Q5_K_M | 5 | ~9,5 GB | Boş yeriniz olduğunda Q4_K_M\'den biraz daha güvenli. |
Q4_K_M | 4 | ~8,5 GB | 12–16 GB kartlar için varsayılan sweet spot. |
Q4_K_S | 4 | ~7,5 GB | Q4_K_M\'den bir adım küçük, biraz daha fazla kalite kaybı. |
Q3_K_M | 3 | ~6,5 GB | Dar bellekte son çare. |
IQ4_XS | ~4,25 | ~7,7 GB | Q4_K_M gibi ama benzer kalitede daha küçük. |
IQ3_XXS | ~3,06 | ~5,5 GB | Şaşırtıcı şekilde kullanılabilir kalite ile çok küçük. |
IQ2_XXS | ~2,06 | ~4 GB | Kahramanca sıkıştırma. Kalite düşer; küçük VRAM\'de devasa modeller için faydalı. |
Diğer model boyutları için sayılar yaklaşık doğrusal olarak ölçeklenir: Q4_K_M\'de 7B model yaklaşık 4,5 GB, Q4_K_M\'de 32B yaklaşık 19 GB, 70B yaklaşık 42 GB. Faydalı bir tahmine en hızlı yol "milyar olarak model parametreleri, ikiye bölünmüş, GB cinsinden Q4_K_M dosya boyutunu verir" küçük bir fudge faktörü ile.
Bir pratik kural olarak kapatalım. Size rahat bir bellek tamponu bırakan en yüksek bit sayısını seçin (KV cache ve overhead için dosya boyutunun birkaç GB üstü). 14B modelle 16 GB GPU\'da bu Q5_K_M veya Q6_K demektir. 12 GB GPU\'da bu Q4_K_M demektir. 8 GB\'ta IQ3 veya IQ4_XS\'e düşün ve biraz kalite maliyetini kabul edin. Yalnızca CPU\'daysanız Q4_K_M veya daha küçüğünü kullanın çünkü token üretimi bant genişliği sınırlıdır ve daha düşük bit sayıları token başına daha az bayt okuma anlamına gelir.
Daha büyük ders, nicemlemenin bir kalite derecesi değil, bir araç olduğudur. Aynı Q4_K_M dosyası donanımınız ve göreviniz için mükemmel olabilir, ya da israflı, ya da yetersiz. Evrensel olarak doğru bir ayar yoktur. Belleğinizin boyutuna ve ihtiyacınız olan hıza uyan ayar vardır, ve isimleri okuyabildiğinizde, üç dosya indirmek yerine ilk denemede onu seçebilirsiniz.