

I want to be careful about the word "designed," because it is doing a lot of work in the version of this argument that gets shared around. The strong claim is that the companies building coding agents have deliberately tuned them to waste your tokens so they can bill you for the waste. I cannot prove intent, and honestly I do not need to. The interesting thing about the current generation of agents is that you do not have to assume any malice at all. You only have to look at how they are paid, how they are trained, and how they run, and notice that all three point the same way: toward producing more. Whether someone in a pricing meeting drew that arrow on purpose or it just fell out of the incentives is, for the user holding the bill, almost beside the point.
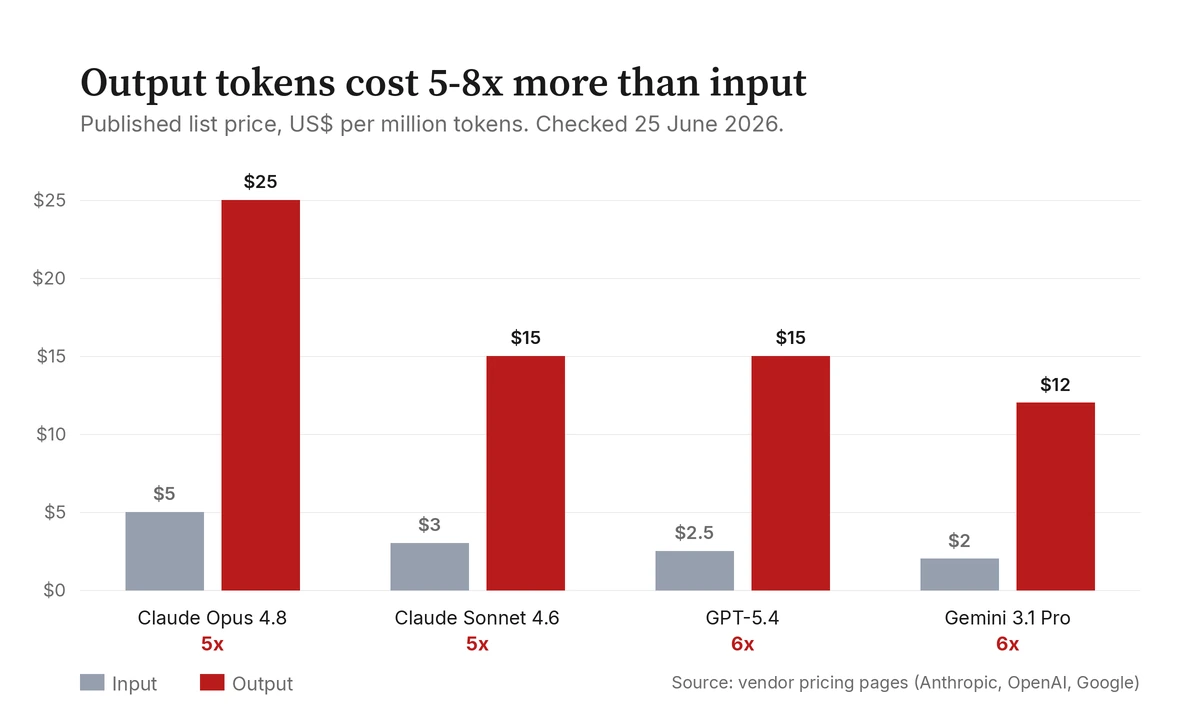
Start with the bill, because it is the least ambiguous part. The big agent models are billed per token, and crucially they are billed asymmetrically: the tokens the model writes cost several times more than the tokens it reads. These are the public list prices on the vendors' own pages, in US dollars per million tokens, which I checked on 25 June 2026. Anything dated is going to drift, so the date matters more than the number; the point is the ratio, and the ratio has been remarkably stable.

| Model | Input $/M | Output $/M | Output multiple |
|---|---|---|---|
| Claude Opus 4.8 (Anthropic) | 5 | 25 | 5× |
| Claude Sonnet 4.6 (Anthropic) | 3 | 15 | 5× |
| GPT-5.4 (OpenAI) | 2.50 | 15 | 6× |
| Gemini 3.1 Pro (Google) | 2 | 12 | 6× |
The Anthropic numbers I read straight off the Claude pricing page; the others are the published API rates for the respective vendors, current as of late June 2026. I am giving you the source and the date precisely so you can go and redo the arithmetic yourself when the prices move, which they will. The shape is what matters: output is the expensive direction, by a factor of roughly five to eight across all three vendors. Every extra sentence the agent writes, every extra file it generates, every "let me also add" lands in the costliest column on the invoice. There is no symmetric force on the other side. Nobody bills the model for being concise.
It would be tempting to stop there and call it a scam, but that would be lazy, and a hostile reader would dismantle it in one line. The output premium is not pure margin. Generating tokens one at a time is genuinely more compute-intensive than reading a prompt you already have in hand, so some of that five-to-eight multiple is real cost, not invented markup. Fine. The argument does not need the premium to be fraudulent. It only needs the premium to exist and to point in a particular direction, which it indisputably does. When the expensive thing and the profitable thing are the same thing, you do not need a conspiracy to predict which way the product drifts.
Now layer on the training, because this is where it stops being only about billing and starts being baked into the model's behaviour. There is a well-documented effect in the literature called length bias. When these models are tuned with human feedback, the reward signal that is supposed to capture "this answer is better" turns out to be heavily correlated with "this answer is longer." In one careful study of the process, the authors found that the measured improvements from the whole expensive alignment procedure were "largely driven by increasing response length, instead of other features," and that a reward based on nothing but length reproduced most of the gains (Singhal et al., 2023). The same bias shows up when a model is used to grade other models: evaluators reliably prefer the longer answer, a tendency the field has a name for, verbosity bias. So the system that decides what "good" looks like has a thumb on the scale for length, independent of whether the longer answer is actually better. The model is not padding to cheat you. It learned, from the way we trained it, that longer reads as better.
The third piece is the one people miss, and it is specific to agents rather than chatbots. A coding agent does not answer once and stop. It runs in a loop: read the files, take an action, read the result, take another action. On every turn it re-sends the relevant context, the conversation so far and the files it is working with, back into the model. That is not an implementation detail you can wish away; it is why prompt caching exists at all. The vendors will happily sell you a discount for re-reading the same context, which is itself the admission that the context is re-read every single turn. Anthropic's own caching, on its own numbers, can cut the cost of that re-reading by up to ninety percent, which is a wonderful deal and also a quiet confirmation of the problem it solves.
Put the three together and you get a compounding effect that is easy to miss in the moment. A bloated file the agent generated on turn three is not paid for once. It sits in the context and gets re-tokenized on turn four, and turn five, and every turn after that until the session ends or the file scrolls out of the window. The agent that scatters fourteen tiny files across your repository has not just written fourteen files; it has signed you up to re-read them, at input rates, for the rest of the session. The verbose architecture, the speculative abstraction, the "I will leave a TODO and come back to it later" that never gets come back to: each of these is a small recurring charge, metered, with no line item that says what it was for.
Let me make that concrete, with every assumption on the table so you can argue with the numbers. This is a back-of-the-envelope illustration, not a benchmark; your real usage will differ, and that is the point of showing the working. Take a one-hour agent session on a premium model at the Opus 4.8 rate of $25 per million output tokens and $5 per million input. Suppose the agent does its job in a reasonably tight way: it generates 40,000 tokens of code and explanation over the hour, and because of the re-read loop it processes 600,000 input tokens across all its turns. That is 40,000 × $25/M plus 600,000 × $5/M, which is $1.00 of output and $3.00 of input, four dollars for the session.
Now suppose the same agent works in the bloated way the incentives quietly favour. It writes 50 percent more, 60,000 output tokens, because longer reads as better and nobody penalised it for sprawl. Those extra files and the longer history mean the per-turn context is larger too, so input climbs to 900,000 tokens. Now it is 60,000 × $25/M plus 900,000 × $5/M, which is $1.50 of output and $4.50 of input, six dollars. Same task, same hour, fifty percent more on the meter, and almost none of that increase showed up as something you asked for. Scale that gap across a team running agents all day, every day, and the "merely fifty percent" becomes the budget line nobody can explain. None of these exact numbers are sacred. Swap in your own token counts and the current prices off the pages I linked, and the direction does not change.
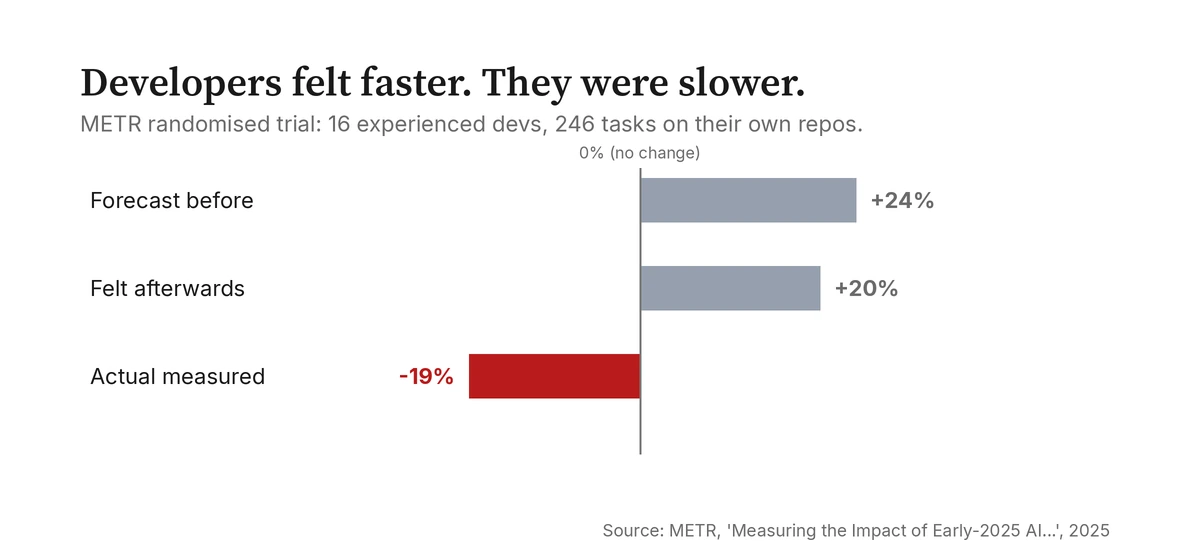
There is evidence that the bloat is not only theoretical and not only about money. GitClear, analysing 211 million changed lines of code from 2020 through 2024, found that copy-pasted code rose from 8.3 to 12.3 percent of all changes while refactored, "moved" code fell from around a quarter of changes to under a tenth; in 2024, for the first time, developers were pasting more than they were consolidating (GitClear, 2025). The Stack Overflow 2025 developer survey, with adoption of AI tools at 84 percent, found the single biggest frustration was "AI solutions that are almost right, but not quite," cited by 66 percent, with another 45 percent saying that debugging AI-generated code costs them more time than it saves (Stack Overflow, 2025). And in a randomised controlled trial that ought to give everyone pause, METR took 16 experienced open-source developers, gave them 246 real tasks on their own mature repositories, and measured what AI tools did to their speed. The developers expected to be sped up by about 24 percent. Afterwards they believed they had been sped up by about 20 percent. They were actually slowed down by 19 percent (METR, 2025). The work that felt like progress was, measured honestly, a net loss, and they could not feel it.
I will be fair to the other side, because the honest version of this argument is more durable than the angry one. METR's study was 16 people on high-standard codebases with early-2025 tooling, and METR itself does not claim it generalises to everyone; the tools have moved since. Google's 2025 DORA report found more than 80 percent of developers feel AI has made them more productive, and its framing is worth keeping in mind: AI "amplifies what's already there," making strong teams stronger and weak processes worse, rather than being simply good or bad (DORA, 2025). There are real tasks where an agent saves me an afternoon, and I am not pretending otherwise. The point is not that agents are useless. The point is that their idea of a good job and your idea of a good job have quietly come apart, and the gap is denominated in tokens.
Here is the part that turns this from an annoyance into something worth writing about. Right now, the tokens are cheap because they are subsidised. The companies selling inference are, by their own published figures, losing extraordinary amounts of money to win the market: OpenAI was reported to be on track for roughly a $5 billion loss on about $3.7 billion of revenue in 2024, which is to say it was spending something like $1.35 for every dollar it took in (CNBC, 2024). That is the water we are all swimming in. The price you pay per token today is a customer-acquisition price, not a sustainable one, and everyone in the industry knows it. We have watched this film before, in ride-hailing, in cloud, in food delivery: the early years are cheap on purpose, the cheapness builds the habit, and then, once the habit is load-bearing, the meter turns real. The subsidy is already starting to lift at the edges: GitHub has moved Copilot onto usage-based AI Credits billing, citing inference costs it can no longer absorb, and the vendors have begun metering the heavy agent workloads that flat-rate plans were never meant to carry.
Now hold that next to the incentives I just laid out, and you do not need to decide whether any of this was intentional to see the trap. While the tokens are cheap, you are learning how to work. You are building the habits, the reflexes, the muscle memory of handing a task to an agent and accepting whatever volume of output it hands back, because at subsidised prices the waste is invisible. And the wasteful habits are exactly the ones that pay off best for the seller when the subsidy ends. A user who has been trained, over a comfortable cheap year, to let an agent generate fourteen files where four would do, to never read the diff, to treat tokens as free, is a far more valuable customer once the meter starts charging what inference actually costs. You do not have to believe anyone planned that. You only have to notice that the cheap period and the verbose habits and the eventual repricing line up a little too neatly to ignore.
So what do I actually want, given all this? Not "stop using agents." That ship has sailed and the tools are genuinely useful in the right hands on the right task. What I want is for the thing I am paying for to be optimised for me rather than for the meter. I want terseness to be the default and not a setting I have to remember to turn on. I want an agent that writes four files when four files are right, that says "this is done" instead of generating three more paragraphs to prove it was thorough, that treats my context window as a scarce resource I am paying to refill on every turn, because I am. The technology to do this exists; the cheaper, more concise models are right there on the same pricing pages. What is missing is the incentive to point them at the user's benefit instead of the invoice.
That is the demand, and it is a reasonable one: build tools that are terse by default, that are measured on the user's outcome and not on output volume, and that treat the token I am paying for as mine and not as the product. Until that is the default, the most useful habit you can build, while the tokens are still cheap, is the one the incentives are quietly training out of you. Read the output. Count the files. Watch the meter. The bill you are not looking at today is the business model someone is counting on tomorrow.