

Every time someone asks why their chatbot got a fact wrong, the honest answer is the same. The model is not looking anything up. It is producing the next word, then the next, then the next, based on patterns it learned from a fixed snapshot of text during training. It has no memory of your codebase, no copy of yesterday's meeting notes, and no idea that the API it is hallucinating was renamed last quarter. It is a brilliant pattern matcher with frozen knowledge, and the most common cure for that limitation is a technique called retrieval-augmented generation, or RAG. The idea is small enough to fit in one sentence, and the engineering around it is interesting enough to fill a career: at query time, find the most relevant passages from a corpus you control, paste them into the prompt, and ask the model to answer using that text. Same model, smarter input.
This article is the long version of that one sentence. I want you to come away with a working mental model: what plain inference is doing, what RAG adds, where the seams are, and how a stack like hydra-llm bakes the whole pipeline into a few commands you can run on your own laptop. No prior machine-learning background needed. Where I have to use a technical term, I will define it before using it.

Plain inference, in the simplest possible terms, is what happens when you type a message into a chat interface and the model writes back. The model is a function. The function takes a sequence of tokens (a token is a sub-word piece, roughly four characters of English on average) and outputs a probability distribution over the next token. The runtime samples one token from that distribution, appends it to the input, and runs the function again. Repeat until the model emits a stop token or hits a length limit. That is the entire trick at the bottom.
The reason this produces sensible answers at all is that the function's parameters, billions of numbers tuned during training, encode an extraordinary amount of statistical regularity about how text is written. Train a model on a large slice of the public web, books, code, and synthetic data, and it learns enough about language and the world that the next-token distribution very often points at the right answer. But everything it knows lives inside those parameters. There is no database the model is consulting. There is no fact-checker. The output is a confident continuation of the input, and confident is not the same as correct.
This is why plain inference fails in three predictable ways. It fails on facts that were not in its training data, like everything that happened after its cutoff date. It fails on facts that were in its training data but are buried under more common alternatives, so the next-token distribution prefers the wrong answer. And it fails on anything specific to you (your code, your contracts, your customers, your private documents) because none of that was in training to begin with. Plain inference cannot fix any of these by trying harder. The information simply is not in the function.
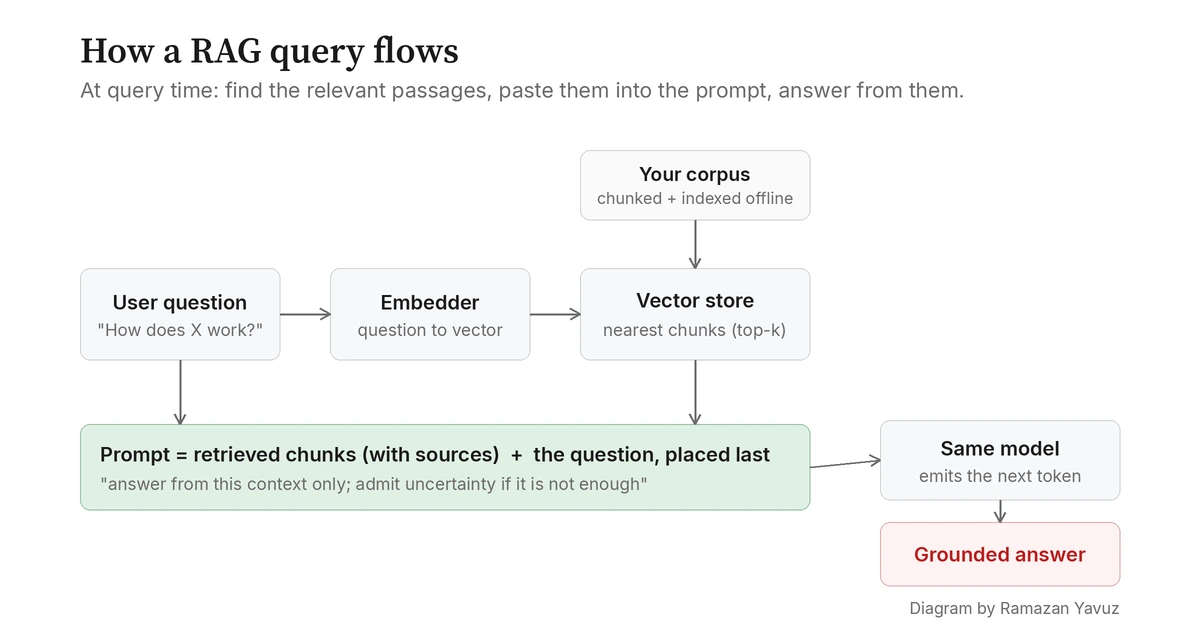
RAG starts from the observation that the function is fine. The model writes excellent prose; it just does not know your facts. So instead of changing the model, change the input. Before sending the user's question to the model, fetch the most relevant passages from a corpus you maintain, glue those passages onto the prompt as context, and let the model do what it is already good at: read text and write a coherent answer based on it.
What changes from the model's point of view is almost nothing. It still receives a prompt and emits the next token, and the next, and the next. What changes is that the prompt now contains the answer, or at least the source the answer can be lifted from. The hard part is not the model. The hard part is finding the right passages.
"The right passages" is where every interesting decision in a RAG system lives. You cannot just paste your entire knowledge base into the prompt; the model has a limited context window (the maximum number of tokens it can read at once) and even when the window is large, more context costs more time, more memory, and more attention budget that the model has to spread thin. So the retrieval step has to be selective: out of however many millions of tokens of source material, surface the few thousand that matter for this specific question.
The trick that makes selective retrieval feasible at scale is called vector search, and the building block underneath it is called an embedding. An embedding is a fixed-size list of numbers (a vector) that represents the meaning of a piece of text. A small embedding might be 384 numbers long; a large one, several thousand. The numbers themselves are not interpretable. What matters is that two pieces of text whose meanings are similar produce vectors that are close to each other in this high-dimensional space, and two pieces of text whose meanings are unrelated produce vectors that are far apart.
You get embeddings from a special kind of language model called an embedder. It looks like a chat model from the outside (you give it text, it gives you something back), but instead of emitting the next token it emits one fixed-size vector summarising the whole input. Embedders are usually small (anywhere from 30 megabytes for a tiny one to a few gigabytes for a large one), much smaller than chat models, because their job is narrower. Some are tuned for prose. Some are tuned for code. The best modern embedders are tuned for both and produce vectors of around 768 to 4096 dimensions.
Once you have an embedder, the indexing step looks like this. Walk through your corpus. Split each document into chunks, which are short, mostly self-contained passages of a few hundred words each. Run every chunk through the embedder. Store the resulting vector, alongside the original text and a pointer back to the source file, in a database that knows how to search by vector similarity. That database is called a vector store; LanceDB, FAISS, and Qdrant are common choices. The result is an index in which every chunk of your knowledge has a coordinate in meaning-space.
Querying the index is the mirror image. Take the user's question. Run it through the same embedder. Now you have a query vector in the same meaning-space as your chunks. Ask the vector store for the chunks whose vectors are closest to it, by some distance measure (cosine similarity is the usual one). The top few chunks come back. Those are your candidates for "passages that probably answer this question." It is, fundamentally, a meaning-aware search engine.
Once retrieval has done its job, prompt assembly is the boring but load-bearing middle step. You take the chunks the vector store returned and you build the actual message you send to the model. There is no single right format, but most systems do something like this: a brief system instruction telling the model how to behave, a delimited block of retrieved context with each chunk labelled by its source, and finally the user's question.
You are an assistant. Answer the user's question using the context below.
If the context does not contain the answer, say you do not know.
<context>
--- src/auth/middleware.go:42-78 ---
func authenticate(r *http.Request) ...
--- README.md:54-72 ---
Auth flow: every request must carry an X-Api-Key header ...
</context>
User question: where do we handle auth tokens?Three small details in this prompt do most of the work. First, the chunks are labelled with their source so the model can cite them and you can verify what it said. Second, the system instruction tells the model to answer from the context only and to admit uncertainty if the context is not enough; without that instruction, models tend to fall back on their trained knowledge and quietly mix it with the retrieved text, which is exactly the failure mode you were trying to avoid. Third, the user's question goes last, because models use the beginning and end of a long context more reliably than the middle (the effect Liu et al. named "lost in the middle"), so a question in the well-attended final position is more likely to stay in focus by the time the model starts answering.
The model then runs ordinary inference. Same function as before. Same next-token loop. The only thing that has changed is that the input now contains the relevant pieces of your corpus, so the most likely next tokens are the ones that draw on that text rather than on the model's frozen training memory.
Stating it as a contrast helps. Plain inference is one round trip: question goes in, answer comes out, the model uses only what it learned at training time. RAG is two round trips: the question first goes to the embedder and the vector store to fetch context, then the question plus that context goes to the chat model. The user sees one box; the system runs two pipelines.
The practical differences fall out from there. Plain inference is faster, because there is only one model call. RAG is more accurate on anything specific to your data, because the answer is grounded in text the model just read. Plain inference can hallucinate confidently because the model has no way to check itself. RAG can also hallucinate, but the chunks are right there in the prompt, so a well-built UI can show them to the user and the answer can be verified. Plain inference cannot tell you about a document you wrote last night, because it was not trained on it. RAG can, because indexing a new document is a one-line operation.
It is worth being honest about what RAG does not fix. RAG does not give the model new reasoning skills; if the underlying model is bad at multi-step reasoning, retrieving good context will not save it. RAG does not eliminate hallucination; the model can misquote, conflate two chunks, or outright ignore the context if your prompt template is sloppy. RAG does not magically protect privacy; if you index a folder full of secrets and then expose the chat to someone, you have just exposed your secrets. RAG is a way to feed better text to a competent model. The model still has to be competent, and the system around it still has to be designed honestly.
There is one more subtlety worth understanding before we get to the local stack. Pure vector search is not the only way to retrieve. There is a much older technique called keyword search (also called lexical search or BM25, after a particular ranking formula) that simply matches the literal words in the query against the literal words in the documents. Vector search is good at meaning ("auth token" finds a chunk that talks about "API key" because the embedder knows they are related). Keyword search is good at exact matches ("X-Api-Key" finds the chunk that contains that exact string, even if no embedder ever heard of it).
The two complement each other. Modern RAG systems often run both, get a list of top results from each, and combine them using a fusion algorithm. The most popular fusion algorithm right now is called Reciprocal Rank Fusion, and it has the pleasing property of being absurdly simple: each result gets a score of 1 / (k + rank) for each list it appears in, the scores are summed, and you sort by the total. k is a small constant, typically 60 in the paper that introduced it. That is the whole formula. The reason it works as well as it does is that it does not need the underlying scores from the two systems to be on the same scale; it only needs them to produce a ranked list. This same fusion idea applies when you index code and prose separately (a code embedder is often better at code and a prose embedder is often better at prose) and you want to query both indexes for one question.
All of the above is theory. To make it concrete I want to walk through how a local RAG stack actually wires the pieces together, and the one I know best is my own. hydra-llm (project page, source on GitHub) is a small CLI that wraps llama.cpp in Docker, exposes an OpenAI-compatible endpoint per model on a stable local port, and treats retrieval as a first-class feature instead of a bolt-on. Everything I am about to describe runs on your own machine, with no cloud, no API key, and no telemetry. The whole point is that nothing leaves the box.
The pieces hydra-llm puts in front of you are exactly the ones the previous sections introduced, with names you can type:
| Concept in the article | Concrete piece in hydra-llm |
|---|---|
| Chat model (the function that writes the answer) | A llama.cpp container running a model from the curated catalog (Llama, Gemma, Qwen, Mistral, etc.) |
| Embedder (the function that turns text into vectors) | A separate llama.cpp container in --embeddings mode, running one of six bundled embedders (nomic-embed-text, qwen3-embed-{0.6b,4b,8b}, bge-m3, nomic-embed-code) |
| Vector store (the database of chunks) | A LanceDB store living in <your-folder>/.hydra-index/, with separate tables for code and prose |
| Hybrid retrieval (vector plus keyword, fused) | Reciprocal Rank Fusion across the code and prose tables, run automatically on every query |
| Prompt assembly (gluing context onto the question) | The chat command's --rag flag: every user message is embedded, top-K chunks are pulled, and the message is wrapped in a <context> block before going to the model |
The choreography from the user's side is short. One command sets up the embedders. One command indexes a folder. One command starts a chat that retrieves on every turn.
# 1. Pull embedders sized to your hardware
hydra-llm rag setup
# 2. Index a folder. Walks the tree, classifies each file as code
# or prose, chunks it line-aware (1500 chars target, 200 overlap),
# embeds each chunk, writes everything to ./.hydra-index/
cd ~/projects/cool-app
hydra-llm index .
# 3. Chat with retrieval on every turn
hydra-llm chat llama-3.1-8b --rag .What happens behind --rag . is exactly the two-pipeline picture from earlier. You type a message. hydra-llm sends it to the embedder container, gets a query vector back, asks LanceDB for the top matching chunks from both the code and prose tables, fuses the two lists with Reciprocal Rank Fusion, takes the top-K survivors, builds a <context> block with each chunk labelled by file path and line range, prepends that to your message, and only then sends the assembled prompt to the chat container. The chat container streams tokens back. Same model, same inference loop, smarter input.
A few details in that pipeline are worth pointing at, because they are the kind of decisions every RAG system has to make and they shape the answers you get. The chunker is line-aware: it never splits a chunk in the middle of a line, which matters for code more than it does for prose. Files are classified before chunking: code files get the code embedder, prose files get the prose embedder, because using a code embedder on a README mangles the prose vector and vice versa. The index moves with the folder: the .hydra-index/ directory sits next to your files, so copying a project to another machine takes the index along for free. Incremental updates are by file modification time and size: re-running hydra-llm index . only re-embeds files that actually changed.
One feature of hydra-llm worth singling out is what it calls catalog-bound bundles. A chat-catalog entry can carry a system prompt, sampling parameters, and a rag_index: path all together as one declarative unit. Once you have create'd a bundle, chatting with it is one word:
hydra-llm create llama-3.1-8b ~/personas/senior-engineer.md cool-app-bot \
--rag-index ~/projects/cool-app
hydra-llm chat cool-app-bot # no flags, retrieval just worksThat is the whole loop, frozen into a name. The bundle says: this model, with this persona, retrieving from this corpus, every turn. It is the difference between explaining a workflow and using it.
For anyone who wants to peek under the floorboards, this is roughly how the pieces are wired in the source. The whole RAG pipeline landed in v0.2.0, in commit 87b27e3 (release tag) and the merge that brought the feature branch into main, commit 0b4c7e1. The branch was split into four reviewable stages, and the design choices each one bakes in are worth naming, because they are the same choices any RAG system has to make.
Stage 1a: 5d6387c embedder catalog. Embedders are treated as a separate model species, not "chat models that happen to embed." They live in their own catalog at ~/.config/hydra-llm/embedders.yaml, with their own download/list/info subcommands and their own port range so they cannot collide with chat models. The decision behind that is mundane and important: an embedder is a long-lived sidecar. It must be running for indexing and for every chat turn that retrieves, but it is otherwise invisible. Modeling it as its own thing keeps that lifecycle honest.
Stage 1b: 44dd621 embedder sidecars and an embeddings client. Each embedder runs in its own llama.cpp container in --embeddings mode, exposing the OpenAI /v1/embeddings shape on a stable port. The client batches requests, normalises vectors (so cosine similarity reduces to a dot product downstream), and lets the rest of the code treat embedding as "give me text, get back a numpy array."
Stage 1c: cb78cd9 walker, classifier, and line-aware chunker. Three honest little functions doing most of the heavy lifting that retrieval quality depends on. The walker respects every .gitignore in the tree, plus a hard-coded blacklist of node_modules, .venv, target, lockfiles, binaries, archives, media, and weights, and it skips files larger than 1 MB or anything that fails a UTF-8 decode. The classifier picks code or prose per file: extension first (so install.sh is correctly code, not prose just because it sits next to a README), then canonical basenames (Makefile, Dockerfile as code; README, LICENSE as prose), then a shebang sniff for extensionless scripts. The chunker has a soft target of 1500 characters with 200 characters of overlap, but it never cuts mid-line, which sounds trivial and is not: a chunk that ends in the middle of a function signature is genuinely useless to retrieval, because the embedder ends up vectoring half a thought.
Stage 1d: 2c98ade LanceDB storage and the index pipeline. This is where it all comes together. Each indexed folder grows a .hydra-index/ with two LanceDB tables (code.lance, prose.lance), a meta.yaml recording which embedder ids the index was built with, and a files.json that lists each indexed file by (path, size, mtime, chunk-ids). Two design decisions in this stage shape the whole user experience: incremental refresh diffs files by (size, mtime) so re-indexing a folder is fast on the second run, and a forced rebuild fires automatically if the recorded embedder ids no longer match what would be picked now, because mixing vectors from different embedders silently destroys retrieval and it is much better to spend a minute re-embedding than to spend a week wondering why answers got worse.
Stage 2: ef7b4cf chat with retrieval and federated query. The chat --rag path embeds each user message, runs k-nearest-neighbour search against both tables, fuses the results with Reciprocal Rank Fusion at k=60, and wraps the survivors in a <context> block before sending the assembled prompt to the chat model. --rag-all federates that retrieval across every indexed folder on the machine; --rag-tag federates across folders that share a tag. Saved chat sessions store the original (un-augmented) text, not the augmented version, so resuming a session does not poison the new turn with stale context.
Stage 3: de360fe catalog-bound bundles. A chat-catalog entry can carry a rag_index: field directly, alongside system_prompt and params. create bakes a model + a persona + a corpus path into one declarative alias, and from that point on, chat <alias> with no flags reproduces the entire workflow. The catalog file is plain YAML you can copy between machines.
Three other decisions show up across the diff and are worth pulling out, because they are the kind of thing you only learn after the second or third RAG system you build. Code and prose use different embedders by default, because a code embedder run on a long README produces a worse vector than a prose embedder, and vice versa; later releases (0e9b939, 687d7ed) made the dual-index optional and single-embedder the new default, because for most user folders the simpler setup retrieves just as well and uses half the disk and half the embedding time. Vectors are normalised at write time, so the LanceDB query path does dot products instead of computing cosine similarity per row. The index is co-located with its source: if you copy ~/projects/cool-app to a different machine, the .hydra-index/ goes along, and the index works there immediately as long as you have the same embedders installed. None of these are exotic; all of them save real time once your indexed corpus is more than a toy.
If you take one thing away from this, let it be the mental model. A language model on its own is a brilliant text continuation engine with frozen knowledge. RAG does not change the engine; it changes the fuel. By inserting a search step in front of the model and feeding the model the most relevant passages from a corpus you control, you turn a closed function with a fixed memory into a system that can answer about your code, your notes, your contracts, or anything else you indexed half a minute ago. The model still has to be good at reading and writing. The retrieval still has to find the right text. The prompt still has to be assembled honestly. When all three pieces are in place, the result is the experience most people imagine when they hear "AI assistant for my own data": fast, grounded, and verifiable, with no mystery cloud step in the middle.
That last bit (no mystery cloud step) is why building this locally is more than a curiosity. The corpus is yours, the embedder is yours, the chat model is yours, and the index never leaves your disk. If your data is sensitive, that is the only architecture that makes sense. If your data is not sensitive, it is still the architecture that gives you the most control and the lowest variable cost. RAG is not a magic layer that fixes language models. It is a careful pipeline that lets you decide what the model is allowed to read before it answers, and once you have run the loop yourself a few times, you will stop being surprised by what models do and do not know.