

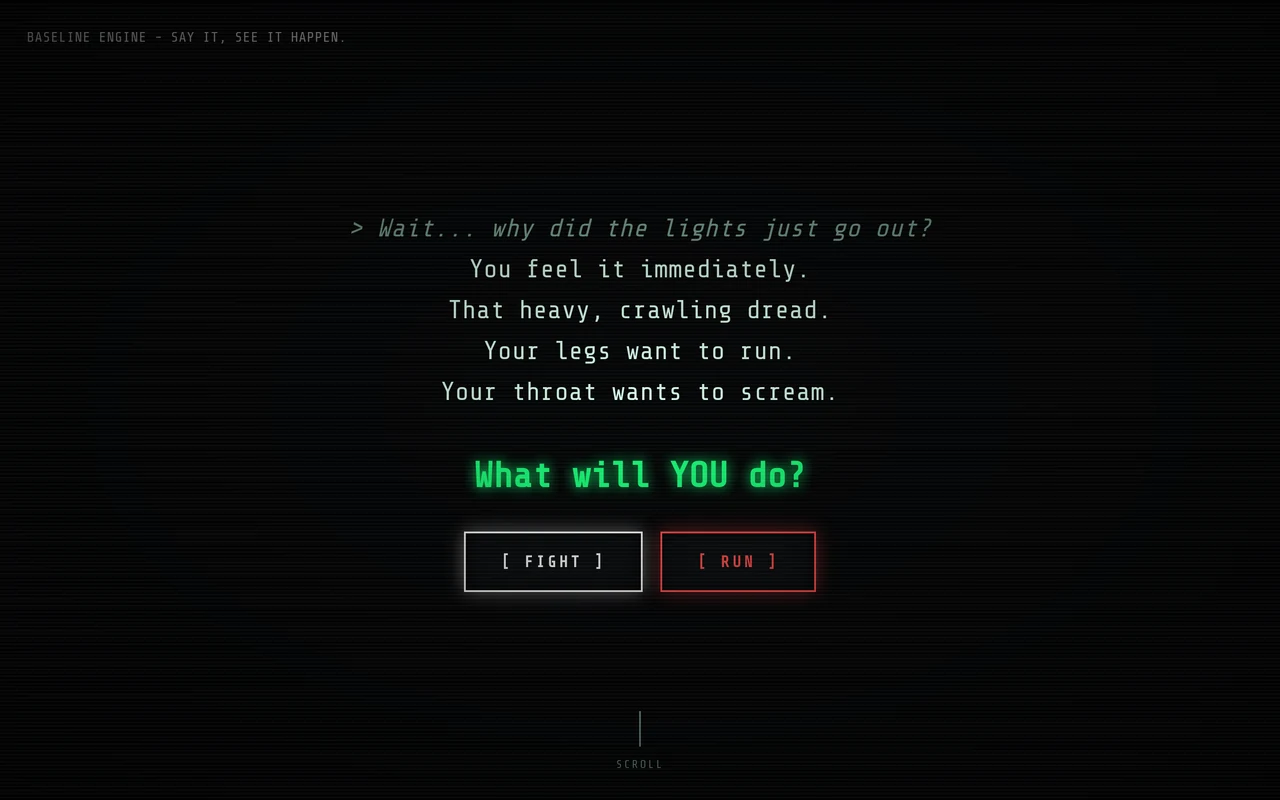
The first text adventures I played as a kid had a recurring frustration. I would type what felt like the obvious thing to do (break the lock, look at the painting closer, ask the man about his daughter) and the game would respond with I don't understand that. So I would type the boring version (break lock, examine painting, talk to man) and the game would respond, but only barely. That is a parser problem disguised as an authoring problem. Every text adventure ever shipped has the same ceiling: the author can only write so many synonyms, and players will always find a phrasing the author did not anticipate. The classic fix was a deeper grammar. The modern fix is to let an LLM do intent recognition, and that is the entire premise of baseline-engine, with a hosted demo at baseline-engine.com.
Baseline Engine is a modular interactive fiction engine. The retro half is a CRT-style PWA terminal at http://localhost:3000 with typewriter animations and sound effects. The modern half is the parser. When a player types something, the engine sends the input plus the current scene's allowed intents to a configured LLM and asks it to pick the right one (or say "no match" if nothing fits). The author writes a scene with intents like inspect_rock, cross_river, talk_to_old_man. The player types I want to check out that weird rock behind me. The model maps it to inspect_rock. The engine resolves the intent through deterministic story logic. The author never wrote a synonym table.
The deterministic part is the design choice that makes the rest viable. The LLM is the parser, not the storyteller. Once the intent is identified, everything downstream is normal game logic: state transitions, inventory checks, branch resolution, scripted text. The model is a translator between the player's English and the author's structured graph.
I tried the other version first. I built a quick prototype where the LLM did the whole thing, generating both the parsing and the response. It was magical for about three minutes. Then two playthroughs of the same scene gave wildly different lore, items appeared and disappeared between turns, and the model contradicted things it had said two messages earlier. This is the well-known problem with using LLMs as game state. They do not have a state. They have a context window, and the context window is approximate.
Baseline-engine treats the model as a pure function: input string plus a list of allowed intents returns the chosen intent. No state in the model. Everything that has to be remembered lives in Redis: scene, inventory, session, history. The model is replaceable. The world is not.
The other half of the engine is a node-based graphical editor at http://localhost:3005. Scenes are nodes, intents are edges, choices branch the graph. Authors do not need to write code. The editor enforces consistency (no orphan links, no scene without exits, no colliding intent IDs), authenticates users with bcrypt-hashed passwords and token sessions, and persists everything to Redis.
CLI and text files would have been simpler and faster for me, the developer. The editor is the thing that makes the engine usable for someone who is not me. The whole point of baseline-engine is to be a tool other people use, and other people are not going to write JSON by hand to add a scene. So the editor exists, and it is now bigger than the engine itself.
By default every story is open. If you load another author's story into the editor, the system automatically forks it: the authorId is reset to your account, and the editor enforces a new title and ID so you cannot accidentally overwrite the original. You get the structure to learn from, the original author keeps their version untouched. Authors can lock stories via Story Properties if they want; locked stories show a lock icon in the game and cannot be opened or forked. The default is open because that is what makes the catalog interesting; the lock exists because some authors will want it. This is borrowed from the open-source ethos applied to fiction.
The model is wrong sometimes. When that happens, the player can correct it: the game offers a "that is not what I meant" affordance with a list of nearby intents. The correction is cached against the original input string, scoped to the current story. The next time anyone types something similar, the cache short-circuits the LLM call and routes directly to the right intent.
This serves two purposes at once. It is a latency optimization, since cached inputs skip the model round-trip. It is also a quality loop: the parser gets better at this story over time, not because the model is learning, but because the corrections accumulate into a phrase-to-intent dictionary that grows with use. The cache ends up doing the same job as a human author writing synonyms, but driven by actual player behavior instead of guesses.
I did not want to ship a game engine that demanded an OpenAI key. The engine speaks to four kinds of backends: Ollama (local, default, my preferred path), OpenAI, Gemini, and a "custom" fallback that is just a generic HTTP endpoint with a model name. The local path is the one I am most proud of. A small instruction-tuned model like Gemma is more than enough for parser duty: it is mapping a sentence onto one of a handful of intents, not writing prose. You can run the engine, host a story, and parse free-form input on your own machine without paying anyone or sending player text to a third party. It will not be the fastest option, but it works, it is private, and it costs nothing.
LLMs as parsers is a much smaller and more reliable application than LLMs as authors. Mapping a free-form sentence to one of N options is something current models do well. Generating consistent fiction across many turns is something they do badly. Build the boundary on the right side of that line and the system becomes usable.
The player correction loop turned out to be the most interesting part of the project, and it was almost an afterthought. The original spec was just "let players retry with a different phrasing." Caching the correction against the input string fell out of trying to avoid re-paying the LLM cost for the same mistake. The fact that it also makes the parser smarter over time was a side effect.
The editor is where the project stands or falls. The engine is fun to write. The engine is useless without authors. Every hour spent on the editor's affordances paid for itself the first time someone who was not me created a scene without asking how.