

Ich möchte mit dem Wort „entworfen“ vorsichtig sein, denn in der Version dieses Arguments, die herumgereicht wird, leistet es eine Menge Arbeit. Die starke Behauptung lautet, die Unternehmen hinter den Coding-Agenten hätten diese bewusst so abgestimmt, dass sie Ihre Tokens verschwenden, um Ihnen die Verschwendung in Rechnung zu stellen. Ich kann keine Absicht beweisen, und ehrlich gesagt muss ich das auch nicht. Das Interessante an der aktuellen Generation von Agenten ist, dass man überhaupt keine böse Absicht annehmen muss. Man muss nur betrachten, wie sie bezahlt, wie sie trainiert werden und wie sie laufen, und bemerken, dass alle drei in dieselbe Richtung zeigen: hin zu mehr Produktion. Ob jemand in einer Preissitzung diesen Pfeil mit Absicht gezeichnet hat oder ob er einfach aus den Anreizen herausfiel, ist für den Nutzer, der die Rechnung hält, fast nebensächlich.
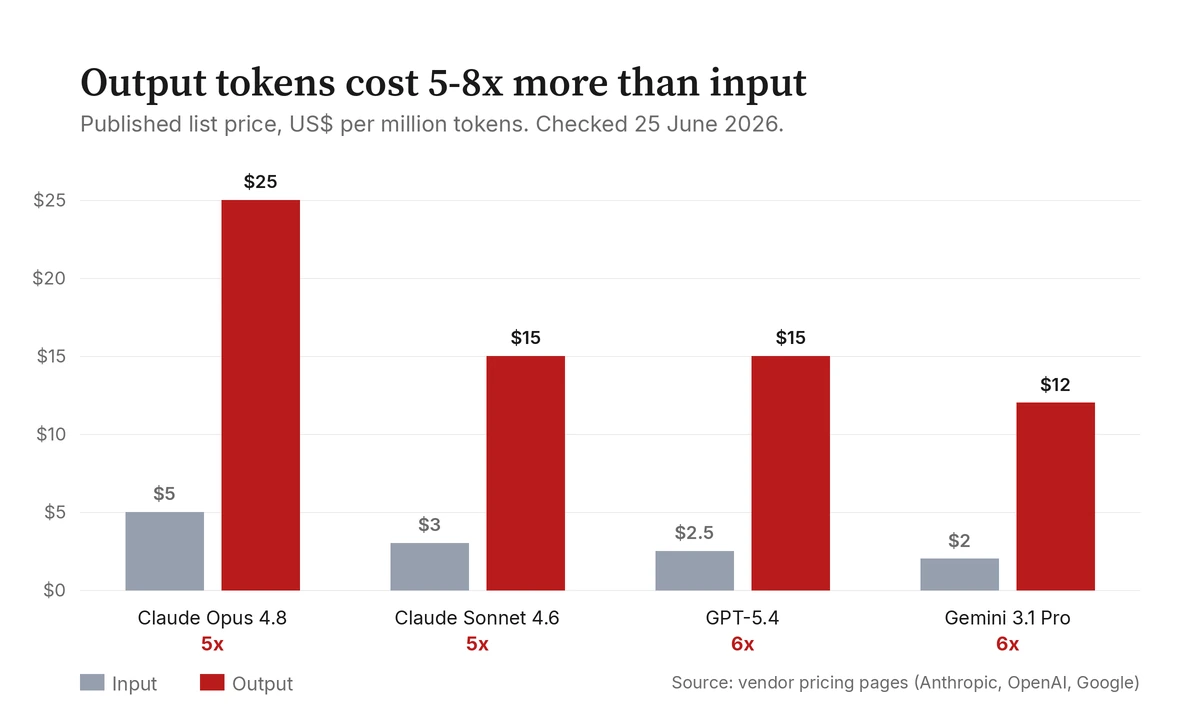
Beginnen wir mit der Rechnung, denn sie ist der eindeutigste Teil. Die großen Agentenmodelle werden pro Token abgerechnet, und zwar entscheidend asymmetrisch: Die Tokens, die das Modell schreibt, kosten ein Vielfaches der Tokens, die es liest. Dies sind die öffentlichen Listenpreise von den eigenen Seiten der Anbieter, in US-Dollar pro Million Tokens, die ich am 25. Juni 2026 geprüft habe. Alles Datierte wird sich verschieben, also zählt das Datum mehr als die Zahl; worauf es ankommt, ist das Verhältnis, und das Verhältnis ist bemerkenswert stabil geblieben.

| Modell | Input $/M | Output $/M | Output-Faktor |
|---|---|---|---|
| Claude Opus 4.8 (Anthropic) | 5 | 25 | 5× |
| Claude Sonnet 4.6 (Anthropic) | 3 | 15 | 5× |
| GPT-5.4 (OpenAI) | 2,50 | 15 | 6× |
| Gemini 3.1 Pro (Google) | 2 | 12 | 6× |
Die Anthropic-Zahlen habe ich direkt von der Claude-Preisseite abgelesen; die anderen sind die veröffentlichten API-Tarife der jeweiligen Anbieter, Stand Ende Juni 2026. Ich nenne Quelle und Datum bewusst genau, damit Sie die Rechnung selbst nachrechnen können, wenn sich die Preise ändern, was sie tun werden. Worauf es ankommt, ist die Form: Output ist die teure Richtung, um den Faktor fünf bis acht bei allen drei Anbietern. Jeder zusätzliche Satz, den der Agent schreibt, jede zusätzliche Datei, die er erzeugt, jedes „ich füge auch noch hinzu“ landet in der teuersten Spalte der Rechnung. Auf der anderen Seite gibt es keine symmetrische Kraft. Niemand stellt dem Modell Knappheit in Rechnung.
Es wäre verlockend, hier aufzuhören und das Ganze einen Betrug zu nennen, aber das wäre bequem, und ein feindseliger Leser würde es in einer Zeile zerlegen. Der Output-Aufschlag ist keine reine Marge. Tokens einzeln zu erzeugen ist tatsächlich rechenintensiver, als einen Prompt zu lesen, den man bereits in der Hand hat, also ist ein Teil dieses Fünf-bis-acht-Faktors echte Kosten, kein erfundener Aufschlag. Gut. Das Argument braucht nicht, dass der Aufschlag betrügerisch ist. Es braucht nur, dass der Aufschlag existiert und in eine bestimmte Richtung zeigt, was er unbestreitbar tut. Wenn das Teure und das Profitable dasselbe sind, braucht man keine Verschwörung, um vorherzusagen, in welche Richtung das Produkt driftet.
Nun kommt das Training hinzu, denn hier hört es auf, nur um Abrechnung zu gehen, und beginnt, im Verhalten des Modells verankert zu sein. In der Forschung ist ein gut dokumentierter Effekt bekannt, der Längenbias heißt. Wenn diese Modelle mit menschlichem Feedback abgestimmt werden, stellt sich heraus, dass das Belohnungssignal, das eigentlich „diese Antwort ist besser“ erfassen soll, stark mit „diese Antwort ist länger“ korreliert. In einer sorgfältigen Untersuchung des Prozesses fanden die Autoren, dass die gemessenen Verbesserungen aus dem gesamten teuren Alignment-Verfahren „weitgehend durch zunehmende Antwortlänge getrieben wurden, statt durch andere Merkmale“, und dass eine Belohnung, die auf nichts als Länge beruhte, die meisten Gewinne reproduzierte (Singhal et al., 2023). Derselbe Bias zeigt sich, wenn ein Modell zur Bewertung anderer Modelle eingesetzt wird: Die Bewerter bevorzugen verlässlich die längere Antwort, eine Tendenz, für die das Feld einen Namen hat, Verbosity-Bias. Das System, das entscheidet, wie „gut“ aussieht, hat also einen Daumen auf der Waage zugunsten der Länge, unabhängig davon, ob die längere Antwort wirklich besser ist. Das Modell pläht nicht, um Sie zu betrügen. Es hat aus der Art, wie wir es trainiert haben, gelernt, dass länger sich wie besser liest.
Das dritte Stück ist das, was die meisten übersehen, und es betrifft speziell Agenten und nicht Chatbots. Ein Coding-Agent antwortet nicht einmal und hört dann auf. Er läuft in einer Schleife: Dateien lesen, eine Aktion ausführen, das Ergebnis lesen, die nächste Aktion ausführen. In jeder Runde sendet er den relevanten Kontext, die bisherige Unterhaltung und die Dateien, an denen er arbeitet, erneut ins Modell. Das ist kein Implementierungsdetail, das man wegwandünschen kann; es ist der Grund, warum es Prompt-Caching überhaupt gibt. Die Anbieter verkaufen Ihnen bereitwillig einen Rabatt für das erneute Lesen desselben Kontextes, was selbst das Eingeständnis ist, dass der Kontext in jeder einzelnen Runde erneut gelesen wird. Das Caching von Anthropic kann nach den eigenen Zahlen die Kosten dieses erneuten Lesens um bis zu neunzig Prozent senken, was ein wunderbares Angebot ist und zugleich eine leise Bestätigung des Problems, das es löst.
Wenn man die drei zusammennimmt, ergibt sich ein sich aufschaukelnder Effekt, der im Moment leicht zu übersehen ist. Eine aufgeblähte Datei, die der Agent in Runde drei erzeugt hat, wird nicht einmal bezahlt. Sie bleibt im Kontext und wird in Runde vier erneut tokenisiert, und in Runde fünf, und in jeder Runde danach, bis die Sitzung endet oder die Datei aus dem Fenster rutscht. Der Agent, der vierzehn winzige Dateien über Ihr Repository verstreut, hat nicht nur vierzehn Dateien geschrieben; er hat Sie dazu verpflichtet, sie zu Input-Tarifen für den Rest der Sitzung erneut zu lesen. Die wortreiche Architektur, die spekulative Abstraktion, das „ich lasse ein TODO und komme später darauf zurück“, auf das niemand zurückkommt: Jedes davon ist eine kleine wiederkehrende Gebühr, gemessen, ohne Posten, der sagt, wofür sie war.
Lassen Sie es mich konkret machen, mit jeder Annahme offen auf dem Tisch, damit Sie mit den Zahlen streiten können. Dies ist eine Überschlagsrechnung zur Veranschaulichung, kein Benchmark; Ihre tatsächliche Nutzung wird abweichen, und genau deshalb zeige ich die Rechnung. Nehmen Sie eine einstündige Agentensitzung auf einem Premium-Modell zum Opus-4.8-Tarif von 25 $ pro Million Output-Tokens und 5 $ pro Million Input. Angenommen, der Agent erledigt seine Aufgabe einigermaßen knapp: Er erzeugt in der Stunde 40.000 Tokens Code und Erklärung, und wegen der Leseschleife verarbeitet er über alle Runden 600.000 Input-Tokens. Das sind 40.000 × 25 $/M plus 600.000 × 5 $/M, also 1,00 $ Output und 3,00 $ Input, vier Dollar für die Sitzung.
Nehmen Sie nun an, derselbe Agent arbeitet auf die aufgeblähte Weise, die die Anreize leise begünstigen. Er schreibt 50 Prozent mehr, 60.000 Output-Tokens, weil länger sich wie besser liest und ihn niemand für Wucherung bestraft hat. Diese zusätzlichen Dateien und die längere Historie bedeuten, dass auch der Kontext pro Runde größer ist, sodass der Input auf 900.000 Tokens steigt. Jetzt sind es 60.000 × 25 $/M plus 900.000 × 5 $/M, also 1,50 $ Output und 4,50 $ Input, sechs Dollar. Dieselbe Aufgabe, dieselbe Stunde, fünfzig Prozent mehr auf dem Zähler, und fast nichts von diesem Anstieg tauchte als etwas auf, worum Sie gebeten hatten. Skalieren Sie diese Lücke über ein Team, das den ganzen Tag Agenten laufen lässt, und aus den „nur fünfzig Prozent“ wird der Budgetposten, den niemand erklären kann. Keine dieser exakten Zahlen ist heilig. Setzen Sie Ihre eigenen Token-Zählungen und die aktuellen Preise von den verlinkten Seiten ein, und die Richtung ändert sich nicht.
Es gibt Belege, dass die Aufblähung nicht nur theoretisch ist und nicht nur ums Geld geht. GitClear analysierte 211 Millionen geänderte Codezeilen von 2020 bis 2024 und fand, dass kopierter Code von 8,3 auf 12,3 Prozent aller Änderungen stieg, während refaktorierter, „verschobener“ Code von rund einem Viertel der Änderungen auf unter ein Zehntel fiel; 2024 fügten Entwickler zum ersten Mal mehr ein, als sie konsolidierten (GitClear, 2025). Die Stack-Overflow-Entwicklerumfrage 2025, mit einer KI-Tool-Nutzung von 84 Prozent, fand als größte Frustration „KI-Lösungen, die fast richtig sind, aber nicht ganz“, genannt von 66 Prozent, während weitere 45 Prozent sagten, das Debuggen von KI-generiertem Code koste sie mehr Zeit, als es spare (Stack Overflow, 2025). Und in einer randomisierten kontrollierten Studie, die allen zu denken geben sollte, nahm METR 16 erfahrene Open-Source-Entwickler, gab ihnen 246 echte Aufgaben in ihren eigenen reifen Repositories und maß, was KI-Tools mit ihrer Geschwindigkeit machten. Die Entwickler erwarteten, um etwa 24 Prozent beschleunigt zu werden. Danach glaubten sie, um etwa 20 Prozent beschleunigt worden zu sein. Tatsächlich wurden sie um 19 Prozent verlangsamt (METR, 2025). Die Arbeit, die sich wie Fortschritt anfühlte, war, ehrlich gemessen, ein Nettoverlust, und sie konnten es nicht spüren.
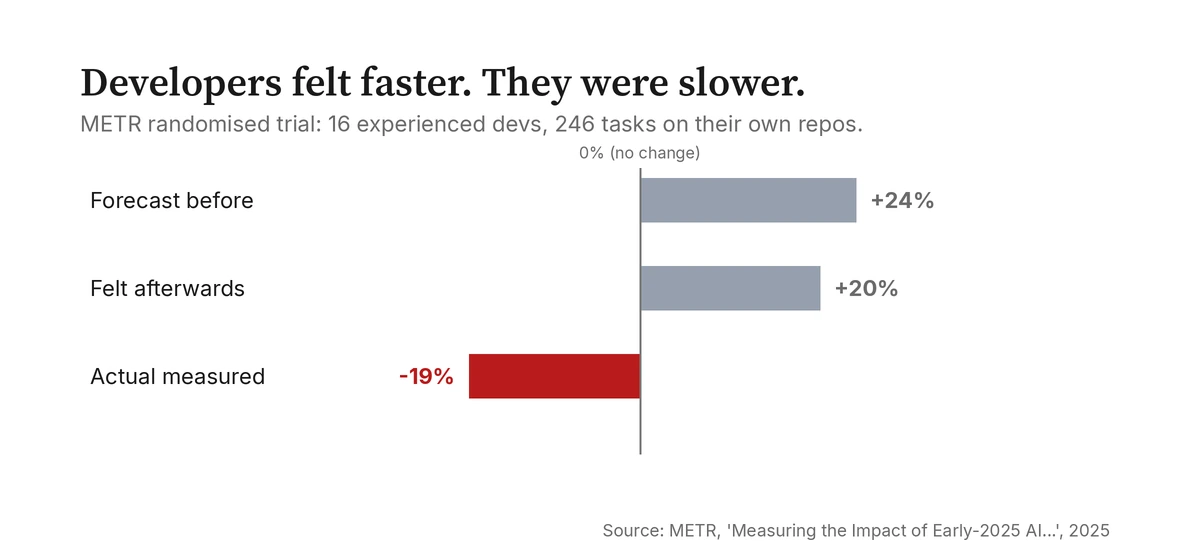
Ich will der Gegenseite gerecht werden, denn die ehrliche Version dieses Arguments ist haltbarer als die wütende. Die METR-Studie umfasste 16 Personen auf Codebasen mit hohen Standards und mit frühen 2025er-Tools, und METR selbst behauptet nicht, dass sie für alle gilt; die Tools haben sich seither weiterentwickelt. Googles DORA-Bericht 2025 fand, dass mehr als 80 Prozent der Entwickler das Gefühl haben, KI habe sie produktiver gemacht, und seine Einordnung ist es wert, im Hinterkopf behalten zu werden: KI „verstärkt, was bereits da ist“, macht starke Teams stärker und schwache Prozesse schlechter, statt einfach gut oder schlecht zu sein (DORA, 2025). Es gibt echte Aufgaben, bei denen mir ein Agent einen Nachmittag spart, und ich tue nicht so, als wäre es anders. Der Punkt ist nicht, dass Agenten nutzlos sind. Der Punkt ist, dass ihre Vorstellung von guter Arbeit und Ihre Vorstellung von guter Arbeit leise auseinandergegangen sind, und die Lücke wird in Tokens beziffert.
Hier ist der Teil, der das Ganze von einem Ärgernis zu etwas macht, über das zu schreiben sich lohnt. Im Moment sind die Tokens billig, weil sie subventioniert sind. Die Unternehmen, die Inferenz verkaufen, verlieren nach ihren eigenen veröffentlichten Zahlen außerordentliche Summen, um den Markt zu erobern: OpenAI war Berichten zufolge 2024 auf Kurs für einen Verlust von rund 5 Milliarden Dollar bei etwa 3,7 Milliarden Dollar Umsatz, also gab es ungefähr 1,35 Dollar für jeden eingenommenen Dollar aus (CNBC, 2024). Das ist das Wasser, in dem wir alle schwimmen. Der Preis, den Sie heute pro Token zahlen, ist ein Kundengewinnungspreis, kein nachhaltiger, und jeder in der Branche weiß das. Diesen Film haben wir schon gesehen, bei Ride-Hailing, bei Cloud, bei Essenslieferdiensten: Die frühen Jahre sind absichtlich billig, die Billigkeit baut die Gewohnheit auf, und dann, sobald die Gewohnheit tragend ist, wird der Zähler echt. Die Subvention beginnt bereits an den Rändern zu schwinden: GitHub hat Copilot auf nutzungsbasierte AI-Credits-Abrechnung umgestellt und nennt Inferenzkosten, die es nicht mehr tragen kann, und die Anbieter haben begonnen, die schweren Agenten-Workloads zu bepreisen, die Flatrate-Pläne nie tragen sollten.
Halten Sie das nun neben die Anreize, die ich gerade dargelegt habe, und Sie müssen nicht entscheiden, ob etwas davon beabsichtigt war, um die Falle zu sehen. Solange die Tokens billig sind, lernen Sie, wie man arbeitet. Sie bilden die Gewohnheiten, die Reflexe, das Muskelgedächtnis, eine Aufgabe einem Agenten zu übergeben und jedes Volumen an Output hinzunehmen, das er zurückgibt, weil bei subventionierten Preisen die Verschwendung unsichtbar ist. Und die verschwenderischen Gewohnheiten sind genau die, die sich für den Verkäufer am besten auszahlen, wenn die Subvention endet. Ein Nutzer, der über ein bequemes, billiges Jahr darauf trainiert wurde, einen Agenten vierzehn Dateien erzeugen zu lassen, wo vier genügen würden, den Diff nie zu lesen, Tokens als kostenlos zu behandeln, ist ein weit wertvollerer Kunde, sobald der Zähler in Rechnung stellt, was Inferenz tatsächlich kostet. Sie müssen nicht glauben, dass das jemand geplant hat. Sie müssen nur bemerken, dass die billige Phase, die wortreichen Gewohnheiten und die schließliche Neubepreisung etwas zu ordentlich aufeinander passen, um sie zu ignorieren.
Was will ich angesichts all dessen also tatsächlich? Nicht „hört auf, Agenten zu benutzen“. Dieser Zug ist abgefahren, und die Tools sind in den richtigen Händen bei der richtigen Aufgabe wirklich nützlich. Was ich will, ist, dass das, wofür ich bezahle, für mich optimiert ist und nicht für den Zähler. Ich will, dass Knappheit die Voreinstellung ist und nicht eine Einstellung, an deren Aktivierung ich denken muss. Ich will einen Agenten, der vier Dateien schreibt, wenn vier Dateien richtig sind, der „das ist fertig“ sagt, statt drei weitere Absätze zu erzeugen, um zu beweisen, dass er gründlich war, der mein Kontextfenster als knappe Ressource behandelt, die ich in jeder Runde neu zu füllen bezahle, denn das tue ich. Die Technik dafür existiert; die billigeren, knapperen Modelle stehen direkt auf denselben Preisseiten. Was fehlt, ist der Anreiz, sie auf den Nutzen des Nutzers zu richten statt auf die Rechnung.
Das ist die Forderung, und sie ist vernünftig: baut Tools, die von Haus aus knapp sind, die am Ergebnis des Nutzers gemessen werden und nicht am Output-Volumen, und die das Token, für das ich bezahle, als meines behandeln und nicht als das Produkt. Bis das die Voreinstellung ist, ist die nützlichste Gewohnheit, die Sie sich aneignen können, solange die Tokens noch billig sind, genau die, die die Anreize Ihnen leise abtrainieren. Lesen Sie den Output. Zählen Sie die Dateien. Behalten Sie den Zähler im Auge. Die Rechnung, die Sie heute nicht ansehen, ist das Geschäftsmodell, auf das jemand morgen zählt.