

Jedes Mal, wenn jemand fragt, warum sein Chatbot einen Fakt falsch wiedergegeben hat, lautet die ehrliche Antwort gleich. Das Modell schlägt nichts nach. Es produziert das nächste Wort, dann das nächste, dann das nächste, anhand von Mustern, die es während des Trainings aus einem festen Textstand gelernt hat. Es hat keine Erinnerung an deine Codebase, keine Kopie der Notizen vom gestrigen Meeting, und keine Ahnung, dass die API, die es gerade halluziniert, im letzten Quartal umbenannt wurde. Es ist ein brillanter Mustererkenner mit eingefrorenem Wissen, und das gängigste Heilmittel gegen diese Einschränkung heißt Retrieval-Augmented Generation, kurz RAG. Die Idee ist klein genug, um in einen Satz zu passen, und das Engineering drumherum interessant genug für eine Karriere: hole zur Anfragezeit die relevantesten Passagen aus einem von dir kontrollierten Korpus, klebe sie in den Prompt, und bitte das Modell, anhand dieses Textes zu antworten. Gleiches Modell, klügerer Input.
Dieser Artikel ist die Langversion dieses einen Satzes. Ich möchte, dass du mit einem funktionierenden Mentalmodell rauskommst: was reine Inferenz tut, was RAG ergänzt, wo die Nahtstellen sitzen, und wie ein Stack wie hydra-llm die ganze Pipeline in ein paar Befehle bündelt, die du auf deinem eigenen Laptop laufen lassen kannst. Kein Vorwissen in Machine Learning nötig. Wo ich einen Fachbegriff brauche, definiere ich ihn vorher.

Reine Inferenz ist in den einfachsten Worten das, was passiert, wenn du eine Nachricht in einer Chat-Oberfläche tippst und das Modell antwortet. Das Modell ist eine Funktion. Die Funktion nimmt eine Token-Sequenz (ein Token ist ein Sub-Wort-Stück, im Englischen im Schnitt etwa vier Zeichen) und gibt eine Wahrscheinlichkeitsverteilung über das nächste Token aus. Die Laufzeit zieht ein Token aus dieser Verteilung, hängt es an den Input und ruft die Funktion erneut auf. Wiederholen, bis das Modell ein Stop-Token ausgibt oder ein Längenlimit erreicht ist. Das ist der ganze Trick, ganz unten.
Der Grund, warum dabei überhaupt sinnvolle Antworten herauskommen, ist, dass die Parameter dieser Funktion, Milliarden Zahlen, die im Training feinjustiert wurden, eine außerordentliche statistische Regelmäßigkeit darüber kodieren, wie Text geschrieben wird. Trainierst du ein Modell auf einer großen Scheibe des öffentlichen Webs, Büchern, Code und synthetischen Daten, lernt es genug über Sprache und Welt, dass die Verteilung über das nächste Token sehr oft auf die richtige Antwort zeigt. Aber alles, was es weiß, lebt in diesen Parametern. Es gibt keine Datenbank, die das Modell konsultiert. Es gibt keinen Faktenchecker. Der Output ist eine selbstbewusste Fortsetzung des Inputs, und selbstbewusst ist nicht dasselbe wie korrekt.
Deshalb scheitert reine Inferenz auf drei vorhersehbare Arten. Sie scheitert an Fakten, die nicht in den Trainingsdaten standen, also an allem, was nach dem Cut-off-Datum passiert ist. Sie scheitert an Fakten, die in den Trainingsdaten standen, aber unter häufigeren Alternativen begraben sind, sodass die Verteilung das falsche bevorzugt. Und sie scheitert an allem, was spezifisch zu dir gehört (dein Code, deine Verträge, deine Kund:innen, deine privaten Dokumente), denn nichts davon war je im Training. Reine Inferenz behebt das nicht durch mehr Anstrengung. Die Information ist schlicht nicht in der Funktion.
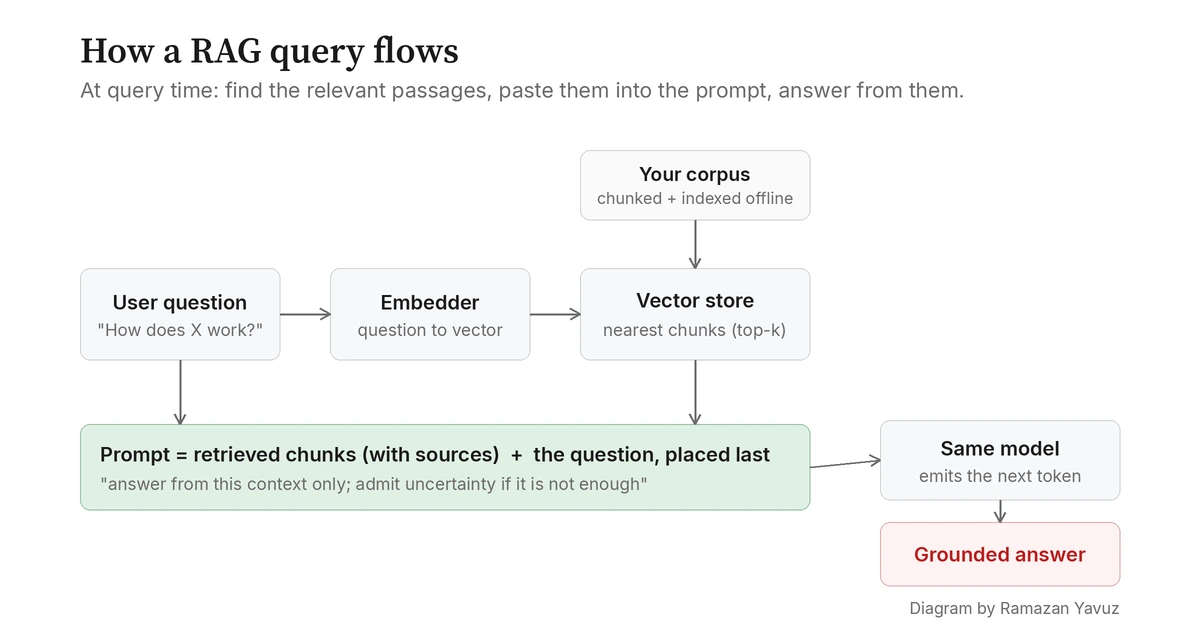
RAG geht von der Beobachtung aus, dass die Funktion in Ordnung ist. Das Modell schreibt ausgezeichnete Prosa; es kennt nur deine Fakten nicht. Statt also das Modell zu ändern, ändere den Input. Bevor du die Frage des Nutzers ans Modell schickst, holst du die relevantesten Passagen aus einem Korpus, den du pflegst, klebst diese Passagen als Kontext an den Prompt, und lässt das Modell tun, worin es sowieso gut ist: Text lesen und auf Basis davon eine kohärente Antwort schreiben.
Aus Sicht des Modells ändert sich fast nichts. Es bekommt weiterhin einen Prompt und gibt das nächste Token aus, und das nächste, und das nächste. Was sich ändert: der Prompt enthält jetzt die Antwort, oder zumindest die Quelle, aus der die Antwort gehoben werden kann. Der harte Teil ist nicht das Modell. Der harte Teil ist, die richtigen Passagen zu finden.
"Die richtigen Passagen" ist die Stelle, an der jede interessante Entscheidung in einem RAG-System lebt. Du kannst nicht einfach deine gesamte Wissensbasis in den Prompt klatschen; das Modell hat ein begrenztes Kontextfenster (die maximale Anzahl Token, die es auf einmal lesen kann), und selbst wenn das Fenster groß ist, kostet mehr Kontext mehr Zeit, mehr Speicher und mehr Aufmerksamkeitsbudget, das das Modell dünn verteilen muss. Der Retrieval-Schritt muss also selektiv sein: aus den vielleicht Millionen Tokens an Quellmaterial die paar tausend an die Oberfläche bringen, die für genau diese Frage zählen.
Der Trick, der selektives Retrieval in großem Maßstab machbar macht, heißt Vektorsuche, und der Baustein darunter heißt Embedding. Ein Embedding ist eine Liste fester Größe aus Zahlen (ein Vektor), die die Bedeutung eines Textstücks repräsentiert. Ein kleines Embedding kann 384 Zahlen lang sein; ein großes mehrere Tausend. Die Zahlen selbst sind nicht interpretierbar. Wichtig ist: zwei Texte, deren Bedeutungen ähnlich sind, ergeben Vektoren, die im hochdimensionalen Raum nah beieinander liegen, und zwei Texte, deren Bedeutungen nichts miteinander zu tun haben, ergeben Vektoren, die weit auseinander liegen.
Embeddings bekommst du von einer speziellen Art Sprachmodell, einem Embedder. Von außen sieht er aus wie ein Chatmodell (du gibst Text rein, du bekommst etwas zurück), aber statt das nächste Token auszugeben, gibt er einen Vektor fester Größe aus, der den ganzen Input zusammenfasst. Embedder sind meist klein (von 30 Megabyte für einen winzigen bis ein paar Gigabyte für einen großen), viel kleiner als Chatmodelle, weil ihr Job enger ist. Manche sind auf Prosa abgestimmt. Manche auf Code. Die besten modernen Embedder sind auf beides abgestimmt und produzieren Vektoren mit etwa 768 bis 4096 Dimensionen.
Sobald du einen Embedder hast, sieht der Indexierungsschritt so aus. Lauf durch deinen Korpus. Spalte jedes Dokument in Chunks, kurze, weitgehend in sich geschlossene Passagen von ein paar hundert Wörtern. Schick jeden Chunk durch den Embedder. Speichere den entstehenden Vektor zusammen mit dem Originaltext und einem Verweis zurück auf die Quelldatei in einer Datenbank, die nach Vektorähnlichkeit suchen kann. Diese Datenbank heißt Vector Store; LanceDB, FAISS und Qdrant sind gängige Wahlen. Das Ergebnis ist ein Index, in dem jeder Chunk deines Wissens eine Koordinate im Bedeutungsraum hat.
Den Index abzufragen ist das Spiegelbild. Nimm die Frage des Nutzers. Schick sie durch denselben Embedder. Jetzt hast du einen Anfragevektor im selben Bedeutungsraum wie deine Chunks. Bitte den Vector Store um die Chunks, deren Vektoren ihm am nächsten sind, nach irgendeinem Distanzmaß (Cosine Similarity ist das übliche). Die paar besten Chunks kommen zurück. Das sind deine Kandidaten für "Passagen, die diese Frage wahrscheinlich beantworten." Im Kern ist es eine bedeutungsbewusste Suchmaschine.
Wenn das Retrieval seinen Job getan hat, ist der Prompt-Aufbau der langweilige, aber tragende Mittelschritt. Du nimmst die Chunks, die der Vector Store zurückgegeben hat, und baust die eigentliche Nachricht, die du ans Modell schickst. Es gibt kein einziges richtiges Format, aber die meisten Systeme machen so etwas: eine kurze System-Anweisung, wie das Modell sich verhalten soll, ein abgegrenzter Block aus abgerufenem Kontext mit Quellen-Label pro Chunk, und am Ende die Frage des Nutzers.
Du bist ein Assistent. Beantworte die Frage anhand des unten stehenden Kontextes.
Wenn der Kontext die Antwort nicht enthält, sag, dass du es nicht weißt.
<context>
--- src/auth/middleware.go:42-78 ---
func authenticate(r *http.Request) ...
--- README.md:54-72 ---
Auth flow: every request must carry an X-Api-Key header ...
</context>
Frage: wo behandeln wir Auth-Tokens?Drei kleine Details in diesem Prompt erledigen die meiste Arbeit. Erstens sind die Chunks mit ihrer Quelle gelabelt, damit das Modell zitieren kann und du nachprüfen kannst, was es gesagt hat. Zweitens weist die System-Anweisung das Modell an, nur aus dem Kontext zu antworten und Unsicherheit zuzugeben, wenn der Kontext nicht reicht; ohne diese Anweisung greifen Modelle gerne aufs trainierte Wissen zurück und mischen es leise mit dem abgerufenen Text, was genau der Fehlermodus ist, den du vermeiden wolltest. Drittens steht die Frage des Nutzers am Ende, weil Modelle den Anfang und das Ende eines langen Kontexts zuverlässiger nutzen als die Mitte (der Effekt, den Liu et al. "lost in the middle" nannten), und eine Frage an der gut beachteten Endposition bleibt eher im Fokus, wenn das Modell zu antworten beginnt.
Dann läuft das Modell ganz normale Inferenz. Dieselbe Funktion wie zuvor. Dieselbe Next-Token-Schleife. Das Einzige, was sich geändert hat: der Input enthält jetzt die relevanten Stücke deines Korpus, also sind die wahrscheinlichsten nächsten Tokens diejenigen, die sich auf diesen Text stützen statt auf die eingefrorene Trainingserinnerung des Modells.
Es als Kontrast auszusprechen, hilft. Reine Inferenz ist ein einziger Roundtrip: Frage rein, Antwort raus, das Modell verwendet nur, was es im Training gelernt hat. RAG sind zwei Roundtrips: die Frage geht zuerst an den Embedder und den Vector Store, um Kontext zu holen, dann gehen Frage und Kontext gemeinsam an das Chatmodell. Der Nutzer sieht eine Box; das System fährt zwei Pipelines.
Die praktischen Unterschiede ergeben sich daraus. Reine Inferenz ist schneller, weil es nur einen Modellaufruf gibt. RAG ist genauer bei allem, was deinen Daten spezifisch ist, weil die Antwort in Text verankert ist, den das Modell gerade gelesen hat. Reine Inferenz kann selbstbewusst halluzinieren, weil das Modell sich nicht selbst überprüfen kann. RAG kann auch halluzinieren, aber die Chunks stehen direkt im Prompt, also kann eine ordentlich gebaute Oberfläche sie dem Nutzer zeigen und die Antwort wird überprüfbar. Reine Inferenz kann dir nichts über ein Dokument sagen, das du gestern Nacht geschrieben hast, weil sie nicht darauf trainiert wurde. RAG schon, weil ein neues Dokument zu indexieren ein Einzeiler ist.
Es lohnt sich, ehrlich darüber zu sein, was RAG nicht behebt. RAG verleiht dem Modell keine neuen Reasoning-Fähigkeiten; wenn das zugrundeliegende Modell schwach im mehrstufigen Schließen ist, rettet es auch der beste Kontext nicht. RAG eliminiert keine Halluzinationen; das Modell kann fehlzitieren, zwei Chunks vermengen oder den Kontext schlicht ignorieren, wenn dein Prompt-Template schludrig ist. RAG schützt nicht magisch die Privatsphäre; wenn du einen Ordner voller Geheimnisse indizierst und dann den Chat irgendjemandem zugänglich machst, hast du gerade deine Geheimnisse offengelegt. RAG ist eine Möglichkeit, einem fähigen Modell besseren Text zu füttern. Das Modell muss trotzdem fähig sein, und das System drumherum muss trotzdem ehrlich entworfen werden.
Eine Feinheit lohnt sich noch, bevor wir zum lokalen Stack kommen. Reine Vektorsuche ist nicht der einzige Weg zu retrieven. Es gibt eine viel ältere Technik namens Schlüsselwortsuche (oder lexikalische Suche, oder BM25, nach einer bestimmten Ranking-Formel), die einfach die wörtlichen Wörter der Anfrage gegen die wörtlichen Wörter der Dokumente abgleicht. Vektorsuche ist gut bei Bedeutung ("Auth-Token" findet einen Chunk, der von "API-Key" spricht, weil der Embedder weiß, dass beide verwandt sind). Schlüsselwortsuche ist gut bei exakten Treffern ("X-Api-Key" findet den Chunk, der genau diese Zeichenkette enthält, selbst wenn kein Embedder je davon gehört hat).
Die beiden ergänzen einander. Moderne RAG-Systeme lassen oft beides laufen, holen sich pro Suche eine Ergebnisliste, und kombinieren sie mit einem Fusionsalgorithmus. Der momentan populärste heißt Reciprocal Rank Fusion, und er hat die angenehme Eigenschaft, absurd einfach zu sein: jedes Ergebnis bekommt für jede Liste, in der es auftaucht, einen Score von 1 / (k + Rang), die Scores werden summiert, und du sortierst nach dem Total. k ist eine kleine Konstante, typischerweise 60 in der Arbeit, die sie eingeführt hat. Das ist die ganze Formel. Der Grund, warum sie so gut funktioniert: sie braucht nicht, dass die zugrundeliegenden Scores beider Systeme auf derselben Skala liegen; sie braucht nur, dass beide eine geordnete Liste produzieren. Genau dieselbe Fusion-Idee greift, wenn du Code und Prosa getrennt indizierst (ein Code-Embedder ist oft besser bei Code, ein Prosa-Embedder oft besser bei Prosa) und beide Indizes gleichzeitig befragen willst.
All das war Theorie. Um sie konkret zu machen, möchte ich durchgehen, wie ein lokaler RAG-Stack die Teile tatsächlich verdrahtet, und der, den ich am besten kenne, ist mein eigener. hydra-llm (Projektseite, Quellcode auf GitHub) ist ein kleines CLI, das llama.cpp in Docker einpackt, pro Modell einen OpenAI-kompatiblen Endpunkt auf einem stabilen lokalen Port bereitstellt und Retrieval als first-class Feature behandelt statt als Aufsatz. Alles, was ich gleich beschreibe, läuft auf deiner eigenen Maschine, ohne Cloud, ohne API-Key, ohne Telemetrie. Der Punkt: nichts verlässt die Box.
Die Bausteine, die hydra-llm vor dich hinstellt, sind genau die aus den vorigen Abschnitten, mit Namen, die du tippen kannst:
| Konzept im Artikel | Konkretes Stück in hydra-llm |
|---|---|
| Chatmodell (die Funktion, die die Antwort schreibt) | Ein llama.cpp-Container mit einem Modell aus dem kuratierten Katalog (Llama, Gemma, Qwen, Mistral, etc.) |
| Embedder (die Funktion, die Text in Vektoren verwandelt) | Ein separater llama.cpp-Container im --embeddings-Modus, mit einem von sechs mitgelieferten Embeddern (nomic-embed-text, qwen3-embed-{0.6b,4b,8b}, bge-m3, nomic-embed-code) |
| Vector Store (die Datenbank der Chunks) | Ein LanceDB-Store in <dein-ordner>/.hydra-index/, mit getrennten Tabellen für Code und Prosa |
| Hybrides Retrieval (Vektor plus Schlüsselwort, fusioniert) | Reciprocal Rank Fusion über die Code- und Prosa-Tabellen, automatisch bei jeder Anfrage |
| Prompt-Aufbau (Kontext an die Frage kleben) | Das --rag-Flag des Chat-Befehls: jede Nutzernachricht wird embedded, die Top-K-Chunks werden geholt, und die Nachricht wird in einen <context>-Block gewickelt, bevor sie ans Modell geht |
Die Choreographie aus Sicht des Nutzers ist kurz. Ein Befehl richtet die Embedder ein. Ein Befehl indiziert einen Ordner. Ein Befehl startet einen Chat, der bei jedem Zug retrieved.
# 1. Embedder passend zur Hardware ziehen
hydra-llm rag setup
# 2. Einen Ordner indizieren. Geht den Baum durch, klassifiziert
# jede Datei als Code oder Prosa, chunked zeilenweise (Ziel 1500
# Zeichen, 200 Overlap), embeddet jeden Chunk, schreibt alles
# nach ./.hydra-index/
cd ~/projects/cool-app
hydra-llm index .
# 3. Chatten mit Retrieval bei jedem Zug
hydra-llm chat llama-3.1-8b --rag .Was hinter --rag . passiert, ist genau das Zwei-Pipeline-Bild von oben. Du tippst eine Nachricht. hydra-llm schickt sie an den Embedder-Container, bekommt einen Anfragevektor zurück, fragt LanceDB nach den besten Chunks aus beiden Tabellen, fusioniert die zwei Listen mit Reciprocal Rank Fusion, nimmt die Top-K-Überlebenden, baut einen <context>-Block mit Pfad und Zeilenbereich pro Chunk, hängt das vor deine Nachricht, und erst dann geht der zusammengesetzte Prompt an den Chat-Container. Der Chat-Container streamt Tokens zurück. Gleiches Modell, gleiche Inferenzschleife, klügerer Input.
Ein paar Details in dieser Pipeline lohnen einen Fingerzeig, weil sie die Art Entscheidung sind, die jedes RAG-System treffen muss, und sie prägen die Antworten, die du bekommst. Der Chunker arbeitet zeilenweise: er splittet einen Chunk nie mitten in einer Zeile, was bei Code mehr zählt als bei Prosa. Dateien werden vor dem Chunken klassifiziert: Code-Dateien gehen an den Code-Embedder, Prosa-Dateien an den Prosa-Embedder, denn ein Code-Embedder über einem README zerstört den Prosa-Vektor und umgekehrt. Der Index wandert mit dem Ordner: das .hydra-index/-Verzeichnis sitzt neben deinen Dateien, also nimmt das Kopieren eines Projekts auf eine andere Maschine den Index mit. Inkrementelle Updates basieren auf Änderungszeit und Größe der Dateien: ein erneutes hydra-llm index . embeddet nur, was sich tatsächlich geändert hat.
Ein Feature von hydra-llm verdient eigene Erwähnung: was es Catalog-bound Bundles nennt. Ein Eintrag im Chat-Katalog kann einen System-Prompt, Sampling-Parameter und einen rag_index:-Pfad als eine deklarative Einheit tragen. Hast du einmal ein Bundle create'd, ist Chatten damit ein einziges Wort:
hydra-llm create llama-3.1-8b ~/personas/senior-engineer.md cool-app-bot \
--rag-index ~/projects/cool-app
hydra-llm chat cool-app-bot # ohne Flags, Retrieval läuft einfachDas ist die ganze Schleife, eingefroren in einen Namen. Das Bundle sagt: dieses Modell, mit dieser Persona, retrievend aus diesem Korpus, jeden Zug. Das ist der Unterschied zwischen einen Workflow erklären und ihn benutzen.
Wer unter die Dielen schauen möchte: so sind die Teile im Quellcode in etwa verdrahtet. Die gesamte RAG-Pipeline kam in v0.2.0, im Commit 87b27e3 (Release-Tag) und im Merge des Feature-Branchs nach main, Commit 0b4c7e1. Der Branch wurde in vier reviewbare Stufen geteilt, und die Designentscheidungen jeder einzelnen sind benennenswert, weil es dieselben Entscheidungen sind, die jedes RAG-System treffen muss.
Stufe 1a: 5d6387c Embedder-Katalog. Embedder werden als eigene Modellspezies behandelt, nicht als "Chatmodelle, die zufällig embedden". Sie leben in ihrem eigenen Katalog unter ~/.config/hydra-llm/embedders.yaml, mit eigenen Download/List/Info-Subkommandos und einem eigenen Port-Bereich, sodass sie nicht mit Chatmodellen kollidieren. Die Entscheidung dahinter ist banal und wichtig: ein Embedder ist ein langlebiger Sidecar. Er muss laufen für die Indexierung und für jeden Chat-Zug, der retrieved, ist sonst aber unsichtbar. Ihn als eigenes Ding zu modellieren, hält diesen Lebenszyklus ehrlich.
Stufe 1b: 44dd621 Embedder-Sidecars und ein Embeddings-Client. Jeder Embedder läuft in seinem eigenen llama.cpp-Container im --embeddings-Modus und exponiert das OpenAI-Format /v1/embeddings auf einem stabilen Port. Der Client batched Requests, normalisiert Vektoren (sodass Cosine Similarity nachgelagert auf ein Skalarprodukt zusammenfällt), und lässt den Rest des Codes Embedding wie "gib mir Text, krieg ein numpy-Array zurück" behandeln.
Stufe 1c: cb78cd9 Walker, Klassifikator und zeilenbewusster Chunker. Drei ehrliche kleine Funktionen, die den Großteil der Schwerstarbeit machen, von der die Retrieval-Qualität abhängt. Der Walker respektiert jede .gitignore im Baum plus eine fest verdrahtete Blacklist von node_modules, .venv, target, Lockfiles, Binaries, Archiven, Medien und Gewichten und überspringt Dateien größer als 1 MB oder solche, die einen UTF-8-Decode nicht überstehen. Der Klassifikator entscheidet pro Datei Code oder Prosa: zuerst Endung (damit install.sh korrekt als Code landet, nicht als Prosa, nur weil es neben einem README liegt), dann kanonische Basisnamen (Makefile, Dockerfile als Code; README, LICENSE als Prosa), dann ein Shebang-Sniff für endungslose Skripte. Der Chunker hat ein Soft-Ziel von 1500 Zeichen mit 200 Zeichen Overlap, schneidet aber nie mitten in einer Zeile, was trivial klingt und nicht ist: ein Chunk, der mitten in einer Funktionssignatur endet, ist fürs Retrieval ehrlich gesagt nutzlos, weil der Embedder einen halben Gedanken vektorisiert.
Stufe 1d: 2c98ade LanceDB-Storage und die Index-Pipeline. Hier kommt alles zusammen. Jeder indizierte Ordner bekommt ein .hydra-index/ mit zwei LanceDB-Tabellen (code.lance, prose.lance), einer meta.yaml, die festhält, mit welchen Embedder-Ids der Index gebaut wurde, und einer files.json, die jede indizierte Datei mit (Pfad, Größe, mtime, Chunk-Ids) auflistet. Zwei Designentscheidungen in dieser Stufe prägen die ganze Nutzererfahrung: inkrementeller Refresh diffed Dateien per (Größe, mtime), sodass Re-Indexierung beim zweiten Lauf schnell ist; und ein erzwungener Rebuild greift automatisch, wenn die festgehaltenen Embedder-Ids nicht mehr zu denen passen, die jetzt gewählt würden, denn das Mischen von Vektoren verschiedener Embedder zerstört Retrieval lautlos, und es ist viel besser, eine Minute neu zu embedden, als eine Woche zu rätseln, warum Antworten schlechter geworden sind.
Stufe 2: ef7b4cf Chat mit Retrieval und föderierte Anfrage. Der chat --rag-Pfad embeddet jede Nutzernachricht, fährt eine k-nächste-Nachbarn-Suche gegen beide Tabellen, fusioniert die Ergebnisse mit Reciprocal Rank Fusion bei k=60, und wickelt die Überlebenden in einen <context>-Block, bevor der zusammengesetzte Prompt an das Chatmodell geht. --rag-all föderiert dieses Retrieval über alle indizierten Ordner der Maschine; --rag-tag föderiert über Ordner, die ein Tag teilen. Gespeicherte Chat-Sessions speichern den ursprünglichen (un-augmentierten) Text, nicht die augmentierte Version, sodass das Wiederaufnehmen einer Session den neuen Zug nicht mit altem Kontext vergiftet.
Stufe 3: de360fe Catalog-bound Bundles. Ein Chat-Katalog-Eintrag kann ein rag_index:-Feld direkt tragen, neben system_prompt und params. create backt Modell + Persona + Korpus-Pfad in einen deklarativen Alias, und ab da reproduziert chat <alias> ohne Flags den ganzen Workflow. Die Katalogdatei ist schlichtes YAML, das du zwischen Maschinen kopieren kannst.
Drei weitere Entscheidungen ziehen sich durch das Diff und sind erwähnenswert, weil es genau die Sorte ist, die man erst nach dem zweiten oder dritten RAG-System lernt, das man baut. Code und Prosa nutzen standardmäßig unterschiedliche Embedder, weil ein Code-Embedder auf einem langen README einen schlechteren Vektor produziert als ein Prosa-Embedder, und umgekehrt; spätere Releases (0e9b939, 687d7ed) machten den Dual-Index optional und Single-Embedder zur neuen Default-Wahl, weil für die meisten Nutzerordner das einfachere Setup genauso gut retrieved und die Hälfte der Plattenfläche und der Embedding-Zeit braucht. Vektoren werden beim Schreiben normalisiert, sodass der LanceDB-Anfragepfad Skalarprodukte rechnet statt Cosine Similarity pro Zeile. Der Index liegt bei seiner Quelle: kopierst du ~/projects/cool-app auf eine andere Maschine, wandert das .hydra-index/ mit, und der Index funktioniert dort sofort, solange du dieselben Embedder installiert hast. Nichts davon ist exotisch; alles davon spart echte Zeit, sobald dein indizierter Korpus mehr ist als ein Spielzeug.
Wenn du eine Sache hier mitnimmst, dann lass es das Mentalmodell sein. Ein Sprachmodell für sich ist eine brillante Textfortsetzungs-Maschine mit eingefrorenem Wissen. RAG ändert die Maschine nicht; es ändert den Treibstoff. Indem du einen Suchschritt vor das Modell schiebst und ihm die relevantesten Passagen aus einem Korpus, den du kontrollierst, fütterst, verwandelst du eine geschlossene Funktion mit fixer Erinnerung in ein System, das zu deinem Code, deinen Notizen, deinen Verträgen oder zu allem antworten kann, was du vor einer halben Minute indiziert hast. Das Modell muss weiterhin gut im Lesen und Schreiben sein. Das Retrieval muss weiterhin den richtigen Text finden. Der Prompt muss weiterhin ehrlich zusammengesetzt werden. Wenn alle drei Stücke sitzen, ist das Ergebnis die Erfahrung, die die meisten Leute sich vorstellen, wenn sie "KI-Assistent für meine eigenen Daten" hören: schnell, geerdet und überprüfbar, ohne mysteriösen Cloud-Schritt in der Mitte.
Genau dieses letzte Stück (kein mysteriöser Cloud-Schritt) ist der Grund, warum es mehr als eine Spielerei ist, das lokal zu bauen. Der Korpus gehört dir, der Embedder gehört dir, das Chatmodell gehört dir, und der Index verlässt deine Platte nicht. Ist deine Datenlage sensibel, ist das die einzige Architektur, die Sinn ergibt. Ist deine Datenlage nicht sensibel, ist es trotzdem die Architektur, die dir die meiste Kontrolle und die geringsten variablen Kosten gibt. RAG ist keine magische Schicht, die Sprachmodelle reparariert. Es ist eine sorgfältige Pipeline, mit der du entscheidest, was das Modell lesen darf, bevor es antwortet, und wenn du die Schleife ein paar Mal selbst gefahren bist, hörst du auf, dich darüber zu wundern, was Modelle wissen und nicht wissen.