

Lokale LLMs kommen in einer verwirrenden Vielfalt von Datei-Varianten. Dasselbe Modell, sagen wir ein 14-Milliarden-Parameter-Mistral, taucht im Repository einer Community-Quantizerin als mistral-14b-Q4_K_M.gguf, mistral-14b-Q5_K_S.gguf, mistral-14b-Q6_K.gguf, mistral-14b-IQ3_XXS.gguf und einem Dutzend weiterer auf. Es ist überall dasselbe Netz von Gewichten, nur unterschiedlich komprimiert. Die Kompression nennen wir Quantisierung, und die Namen sagen dir genau, welche Form von Kompression angewendet wurde. Sobald du sie lesen kannst, hörst du auf zu raten.
Ein neuronales Netz ist eine sehr lange Liste von Zahlen. Diese Zahlen sind Gewichte, und während des Trainings wurden sie als 32-Bit- oder 16-Bit-Fließkommazahlen gespeichert. Ein 7-Milliarden-Parameter-Modell in 16-Bit ist 14 GB Gewichte. Ein 70-Milliarden-Parameter-Modell in 16-Bit ist 140 GB. Die meisten Consumer-GPUs können beides nicht halten, und selbst System-RAM hat mit den größeren Modellen Mühe. Also komprimieren wir.
Quantisierung ist ein schickes Wort für "speichere jedes Gewicht in weniger Bits". Wenn ein Gewicht, das 16 Bit benötigte, mit 4 Bit angenähert werden kann, wird die Datei viermal kleiner. Das Modell läuft trotzdem; es läuft nur aus einer leicht weniger präzisen Version seiner selbst. Die Kunst liegt darin zu wählen, wo man Präzision verliert, sodass der Verlust das Verhalten des Modells nicht zerstört.
Reine 4-Bit-Speicherung wäre das einfachste Schema: nimm jedes Gewicht, wähle den nächstgelegenen darstellbaren Wert aus 16 Möglichkeiten, speichere den Index. Das funktioniert, aber es geht zu viel verloren. Moderne Formate sind klüger. Sie gruppieren Gewichte in kleine Blöcke (typischerweise 32 Werte pro Block) und speichern innerhalb jedes Blocks einen geteilten Skalierungsfaktor und manchmal einen Offset. Anstatt "dieses Gewicht ist die Ganzzahl 5 aus 0..15" ist es also "dieses Gewicht ist 5 aus 0..15, multipliziert mit der Skala 0,0042 des Blocks, mit dem Offset des Blocks dazu addiert". Diese kleine Per-Block-Kalibrierung holt den größten Teil der Präzision zurück.
Daher kommen die Buchstaben in den Namen. K steht für k-Quants, die Familie von Formaten, die Iwan Kawrakow in llama.cpp eingeführt hat und die diese Per-Block-Skalen (und ein paar andere Tricks) nutzt, um ein deutlich besseres Verhältnis von Qualität zu Größe zu erreichen als naive Bit-Trunkierung. I steht für importance-aware Quantisierung, bei der das Format mehr Bits für Gewichte ausgibt, auf die das Modell stark angewiesen ist, und weniger Bits für Gewichte, die weniger beitragen. So bewahrt das Modell seine Schärfe in den Teilen, die zählen.
Die Namen folgen einem Muster. Der erste Teil ist das Speicherschema, der zweite Teil ist die Bit-Anzahl, und das Suffix ist die Größenvariante. Lass mich die häufigsten durchgehen, denen du tatsächlich begegnen wirst.
Q2_K, Q3_K, Q4_K, Q5_K, Q6_K, Q8_K: k-Quant-Formate mit 2, 3, 4, 5, 6 und 8 Bits pro Gewicht. Höhere Zahl heißt mehr Bits pro Gewicht, was größere Datei und bessere Qualität bedeutet. Q8_K ist im Wesentlichen nicht von der ursprünglichen 16-Bit-Datei zu unterscheiden. Q2_K ist stark komprimiert und merklich schlechter.
Das Suffix _S, _M oder _L ist die Größenvariante innerhalb eines Bit-Budgets. Sie steuern, wie das Format sein Bit-Budget über verschiedene Teile des Modells verteilt. _S ist am kleinsten und aggressivsten. _L ist am größten und großzügigsten. _M liegt in der Mitte.
IQ1_S, IQ2_XS, IQ2_XXS, IQ2_S, IQ3_XXS, IQ3_XS, IQ3_S, IQ3_M, IQ4_XS, IQ4_NL: importance-aware Varianten. Gleiche Lesart: Zahl ist Bits pro Gewicht, Suffix ist Größenvariante. Die XXS- und XS-Größen sind aggressive Niedrig-Bit-Einstellungen, die erst durch die Importance-Awareness praktikabel wurden; ohne sie wäre Sub-3-Bit-Quantisierung für die meisten Modelle unbrauchbar gewesen.
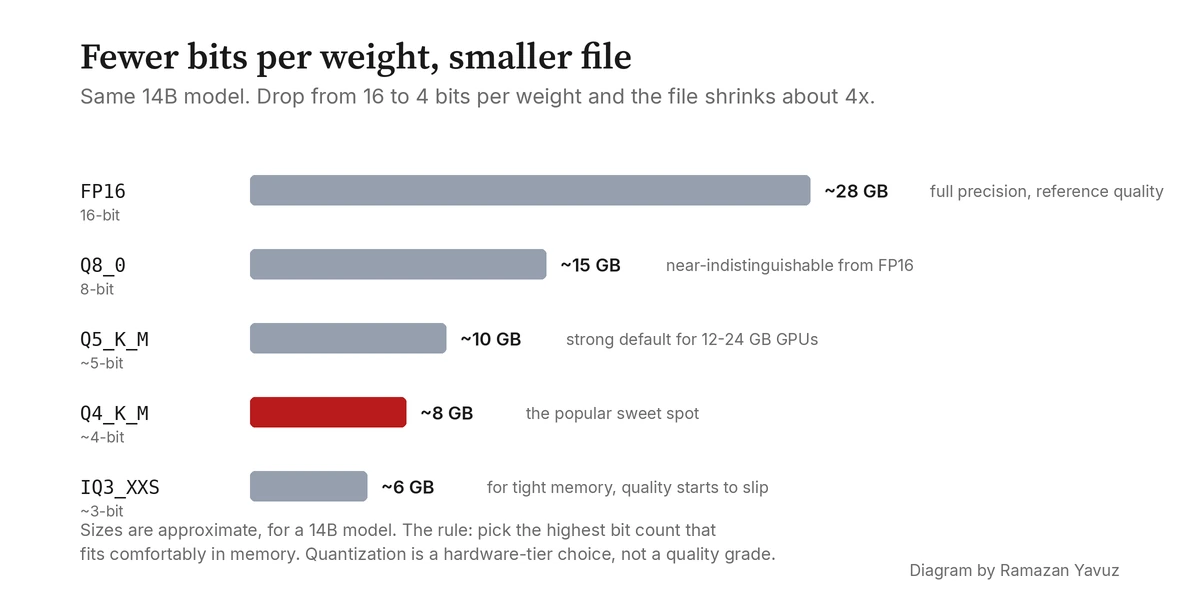
Ein 14-Milliarden-Parameter-Modell gibt dir ein Gefühl für den Trade-off. In F16 (dem ursprünglichen 16-Bit-Format) sind es etwa 28 GB auf der Platte und genauso viel im Speicher. In Q8_K schrumpft es auf rund 15 GB mit Qualitätsverlust, den du auf den meisten Benchmarks nicht messen kannst. In Q6_K sind es etwa 11 GB mit Qualitätsverlust, den du im Gespräch nicht messen kannst. In Q4_K_M sind es etwa 8,5 GB; das ist der Sweet Spot, auf dem die meisten Leute für Consumer-GPUs landen, und es ist die Stufe, auf die ich in der Tier-Konfiguration von hydra-llm defaulte. Der Qualitätsverlust ist klein, beginnt aber bei harten Prompts messbar zu werden.
Darunter degradieren die Dinge schneller. Q3_K_M liegt bei rund 6,5 GB, aber das Modell wird bei langen, strukturierten Aufgaben verwirrter. Q2_K liegt bei rund 5 GB und beginnt sichtbar schlechtere Outputs zu produzieren. IQ3_XXS, obwohl nur etwa 5,5 GB, übertrifft oft Q3_K_S bei gleicher Größe, weil sein Bit-Budget klüger verteilt ist. Das ist die Ein-Satz-Zusammenfassung von importance-aware Quantisierung: kleinere Dateien bei gleicher Qualität, oder bessere Qualität bei gleicher Größe.

Hardware entscheidet, was du laufen lassen kannst. Die erste Beschränkung ist Speicher. Das Modell muss in den VRAM deiner GPU passen (oder, wenn du nur CPU-Inferenz machst, in den System-RAM mit etwas Headroom für das OS). Wenn deine GPU 12 GB VRAM hat und die Modelldatei 14 GB ist, kannst du sie nicht laden; du musst auf eine kleinere Quantisierung herunter oder das Modell zwischen CPU und GPU aufteilen, was es deutlich verlangsamt.
Die zweite Beschränkung ist Bandbreite. Niedrigere Bit-Quantisierungen lesen weniger Bytes pro Gewicht, was bedeutet, dass mehr Gewichte pro Sekunde gezogen werden. Auf bandbreitenlimitierter Hardware (was die meisten Consumer-GPUs und fast alle integrierten GPUs sind) laufen niedrigere Bit-Quantisierungen tatsächlich schneller, nicht nur kleiner. Ein Q4_K_M produziert Tokens oft 1,5- bis 2-mal schneller als dasselbe Modell in Q8_K, weil die GPU einfach weniger Daten umherschiebt.
Deshalb behandle ich Quantisierung als Hardware-Tier-Entscheidung statt als Qualitäts-Entscheidung. Wähl die höchste Bit-Anzahl, die bequem in den Speicher passt und dir tolerable Geschwindigkeit gibt; das ist dein Sweet Spot. Für die meisten modernen Consumer-GPUs mit 12 bis 24 GB ist Q4_K_M bis Q6_K das praktische Band. Für Maschinen mit sehr knappem Speicher-Budget bieten die IQ-Formate einen klügeren Weg nach unten.
Ein paar gängige Bezeichnungen, in eine Tabelle für die schnelle Referenz zusammengefasst. Größenangaben sind ungefähr für ein 14-Milliarden-Parameter-Modell.
| Name | Bits/Gewicht | Ungef. Größe (14B) | Wann benutzen |
|---|---|---|---|
F16 / BF16 | 16 | ~28 GB | Du hast den Speicher und willst das Original. |
Q8_K | 8 | ~15 GB | Effektiv-Original-Qualität bei halber Größe. |
Q6_K | 6 | ~11 GB | Hervorragende Qualität, passt bequem auf 16-GB-Karten. |
Q5_K_M | 5 | ~9,5 GB | Etwas sicherer als Q4_K_M, wenn du Headroom hast. |
Q4_K_M | 4 | ~8,5 GB | Default-Sweet-Spot für 12–16 GB-Karten. |
Q4_K_S | 4 | ~7,5 GB | Eine Stufe kleiner als Q4_K_M, leicht mehr Qualitätsverlust. |
Q3_K_M | 3 | ~6,5 GB | Letzter Ausweg bei knappem Speicher. |
IQ4_XS | ~4,25 | ~7,7 GB | Wie Q4_K_M, aber kleiner bei ähnlicher Qualität. |
IQ3_XXS | ~3,06 | ~5,5 GB | Sehr klein mit überraschend brauchbarer Qualität. |
IQ2_XXS | ~2,06 | ~4 GB | Heroische Kompression. Qualität fällt; nützlich für riesige Modelle auf winzigem VRAM. |
Für andere Modellgrößen skalieren die Zahlen ungefähr linear: ein 7B-Modell in Q4_K_M ist rund 4,5 GB, ein 32B in Q4_K_M ist rund 19 GB, ein 70B ist rund 42 GB. Der schnellste Weg zu einer brauchbaren Schätzung lautet "Modellparameter in Milliarden, durch zwei geteilt, ergibt die Q4_K_M-Dateigröße in GB" mit einem kleinen Fudge-Faktor.
Eine praktische Faustregel zum Abschluss. Wähl die höchste Bit-Anzahl, die dir ein bequemes Speicher-Polster lässt (ein paar GB über der Dateigröße für KV-Cache und Overhead). Auf einer 16-GB-GPU mit einem 14B-Modell heißt das Q5_K_M oder Q6_K. Auf einer 12-GB-GPU heißt das Q4_K_M. Auf 8 GB geh runter auf IQ3 oder IQ4_XS und nimm etwas Qualitätskosten in Kauf. Wenn du nur CPU benutzt, nutz Q4_K_M oder kleiner, weil Token-Generierung bandbreitenlimitiert ist und niedrigere Bit-Anzahlen weniger Bytes pro Token bedeuten.
Die größere Lehre ist, dass Quantisierung ein Werkzeug ist, kein Qualitätsgrad. Dieselbe Q4_K_M-Datei kann perfekt für deine Hardware und Aufgabe sein, oder verschwenderisch, oder unzureichend. Es gibt keine universell richtige Einstellung. Es gibt die Einstellung, die zur Größe deines Speichers und der benötigten Geschwindigkeit passt, und sobald du die Namen lesen kannst, kannst du sie beim ersten Versuch wählen, statt drei Dateien herunterzuladen, um es herauszufinden.