

Es gibt zwei Lager, wenn es darum geht, KI-Agenten in Operations einzusetzen. Das eine sagt, gib ihnen vollen Zugriff, lass sie laufen, sie sind smart genug. Das andere sagt, gib ihnen nichts, sie sind unzuverlässig und werden Production zerlegen. Beide haben recht. Beide sind unbrauchbar als Strategie. Clauding ist mein Versuch, eine dritte Antwort zu geben: gib Agenten reale Workflows, aber bau die Grenzen so, dass ein Fehler des Agenten nichts kaputt macht, das nicht in einer Minute rückgängig zu machen ist.
Die Schwierigkeit mit aktuellen Agent-Setups in Operations-Kontexten ist nicht, dass die Agenten nicht fähig wären. Sie sind sehr fähig. Die Schwierigkeit ist, dass die Setups binär sind. Entweder ein Agent hat Schreibzugriff auf den Cluster, oder er hat keinen. Entweder er kann kubectl apply, oder er kann nichts. Entweder er rebootet die Datenbank, oder er liest nur Log-Zeilen.
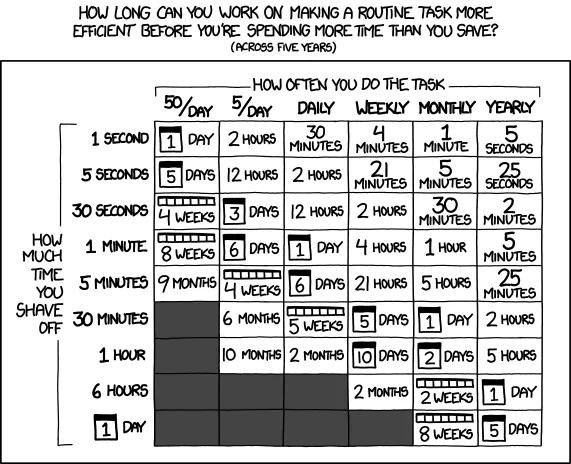
Diese Binärität existiert, weil die Werkzeuge, die wir haben, für Menschen gebaut sind. Ein Mensch hat Zugang zu einem Cluster oder hat ihn nicht. Ein Mensch ist einer Approval-Workflow eingebaut, weil er warten kann. Ein Agent ist nicht in einer Approval-Workflow eingebaut, weil niemand sich überlegt hat, was es heißen soll, wenn ein Agent auf eine Approval wartet. Also bekommt er entweder alles oder nichts.
Das Resultat ist, dass die meisten produktiven Agent-Setups, die ich sehe, entweder gefährlich sind (alles, kein Audit) oder nutzlos sind (lesen-only, kein echter Workflow). Es gibt sehr wenig dazwischen.
Clauding gibt einem Agent ein Set von erlaubten Aktionen, jede mit einer eigenen Policy. Eine Policy kann sein: tue es einfach. Sie kann sein: tue es, aber logge es. Sie kann sein: warte auf eine menschliche Approval, dann tue es. Sie kann sein: tue es, aber ich kann es jederzeit zurückdrehen. Sie kann sein: tue es, aber nur in dieser Umgebung. Sie kann sein: tue es, wenn diese fünf Vorbedingungen erfüllt sind.
Wichtig ist, dass jede einzelne Aktion ihre eigene Policy hat. Ein Agent darf typischerweise frei kubectl logs rennen, aber jeder kubectl apply hat eine Policy, die ihn auf eine Approval-Queue legt. git push in einen Feature-Branch ist policy-frei. git push in main ist es nicht. Das ist nicht clever. Das ist die Art, wie Menschen ohnehin schon arbeiten – und der Punkt ist, dass die Agent-Tooling diese Form annehmen muss, nicht eine binäre.
Die andere Seite davon ist, dass jede Aktion einen Audit-Eintrag bekommt. Wer hat sie ausgelöst, mit welchem Prompt, welcher Output, welche Policy hat sie passiert, ob sie zurückgenommen wurde. Das ist der Audit-Trail, den ein Mensch in Operations sowieso braucht. Wenn der Agent ihn nicht produziert, produziert ihn niemand.
Clauding sitzt zwischen dem Agent und der Welt als ein Tool-Provider. Der Agent kennt eine Liste von "Tools" mit klar dokumentierten Schemata. Wenn der Agent eines aufruft, geht der Aufruf an Clauding, das die Policy auswertet, gegebenenfalls auf Menschen wartet, die Aktion ausführt und die Antwort zurückgibt. Aus Sicht des Agents ist das ein synchroner Tool-Call mit eventuell langer Latenz. Aus Sicht der Operations-Crew ist das ein normaler Approval-Workflow mit Logs.
Die Policies werden in einer einfachen YAML-Datei beschrieben, in der jede Aktion eine Liste von Conditions und ein Approval-Verhalten hat. Es gibt keinen Pluggin-Mechanismus, kein DSL, keine Custom-Engine. Wenn man eine komplexere Bedingung will als das, was in YAML auszudrücken ist, schreibt man eine Funktion, die als externes Webhook-Endpoint läuft, und das wird in der Policy referenziert. Das hält das Policy-System einfach und schiebt Komplexität dahin, wo sie hingehört.
Rollback ist eine first-class-Operation. Jede Aktion, die Clauding ausgeführt hat, kann zurückgenommen werden, vorausgesetzt die Aktion selbst hat einen Rollback-Befehl mitgeliefert. git push hat einen git revert. kubectl apply hat ein kubectl apply mit dem vorigen Manifest. terraform apply hat ein terraform apply mit dem vorigen Plan. Das macht den Audit-Trail nicht nur informativ, sondern operativ.
Der Pitch von Clauding ist nicht, einen Assistenten zu haben, der dir vorschlägt, was du tun könntest. Davon gibt es genug. Der Pitch ist, einen Operator zu haben, der Dinge tatsächlich tut, mit den gleichen Sicherheitsnetzen wie ein Mensch im selben Job. Approval-Queues, Audit-Logs, Rollback-Schalter, Umgebungsgrenzen.
Das ist eine andere Art, über Agenten zu denken, als wir es bisher hatten. Es behandelt sie nicht als magische Wesen, sondern als Identitäten in einer Operations-Welt, die ohnehin schon Identitäten kennt. Ein Agent ist kein User mit einem festen Set von Berechtigungen, aber er ist auch kein "AI" mit unbeschränkten Möglichkeiten. Er ist ein Akteur mit einem Set von Aktionen und einer Policy auf jede Aktion. Das ist es.
Clauding ist Open Source und absichtlich klein. Die Codebase ist überschaubar, die Policies sind in YAML, die Audit-Logs sind in einer SQLite-Datenbank, die du jederzeit auf eine andere Storage migrieren kannst. Es gibt keinen Hosted-Service, keinen Plan, einen zu bauen, kein Go-to-Market.
Was es gibt, ist eine Spec, die andere Tools übernehmen können, und ein Referenz-Setup, das in der eigenen Infra läuft. Wenn das Konzept überlebt, soll es in deiner CI laufen, in deiner eigenen Cluster, mit deiner eigenen Audit-Backend, ohne dass jemand wissen muss, dass du es nutzt. So sah Sicherheits-Tooling immer aus, bevor sich alles zu Plattformen entwickelt hat. Das ist die Form, die Operations-Tooling wieder annehmen sollte.